环境:
- 语言:php7.4
- 框架:hyperf 2.0
服务器
- nginx 1 台
- php api 4 台
- redis 1 台
- mysql 1 台
问题描述
- 目前项目在 qps 较高时遇到了响应时间延长的问题,新增了一台 api 服务器,并没有多大改善(原本是 3 台)
- 大概看了一下高并发时服务器的负载,并没有达到上限
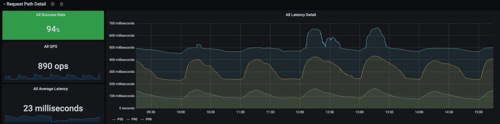
- 平时 qps 可以支撑 1000 左右(3 台服务器),响应延迟保持在 450ms 左右。这两天请求增多 qps 达到 1300 左右,每个小时有十几分钟响应延迟会增加(多的时候响应会达到 3 、4 秒)(下面会附图),前 2 条大概排除了服务器的问题,现在考虑代码问题。下面附图把代码流程加了 time debug,并附带上比较耗时的代码段,麻烦各位大佬帮忙看看代码有没有性能瓶颈问题。
ps: 之前有段时间也遇到响应延迟问题,当时 time debug 定位到 redis get 操作耗时比较多(当时是 2 秒左右),但并没有在这方面做修复,后面通过减少了 swoole 的进程数解决了。
请求延迟监控图
每个小时的开始,请求会比较集中
请求流程时间拆分图
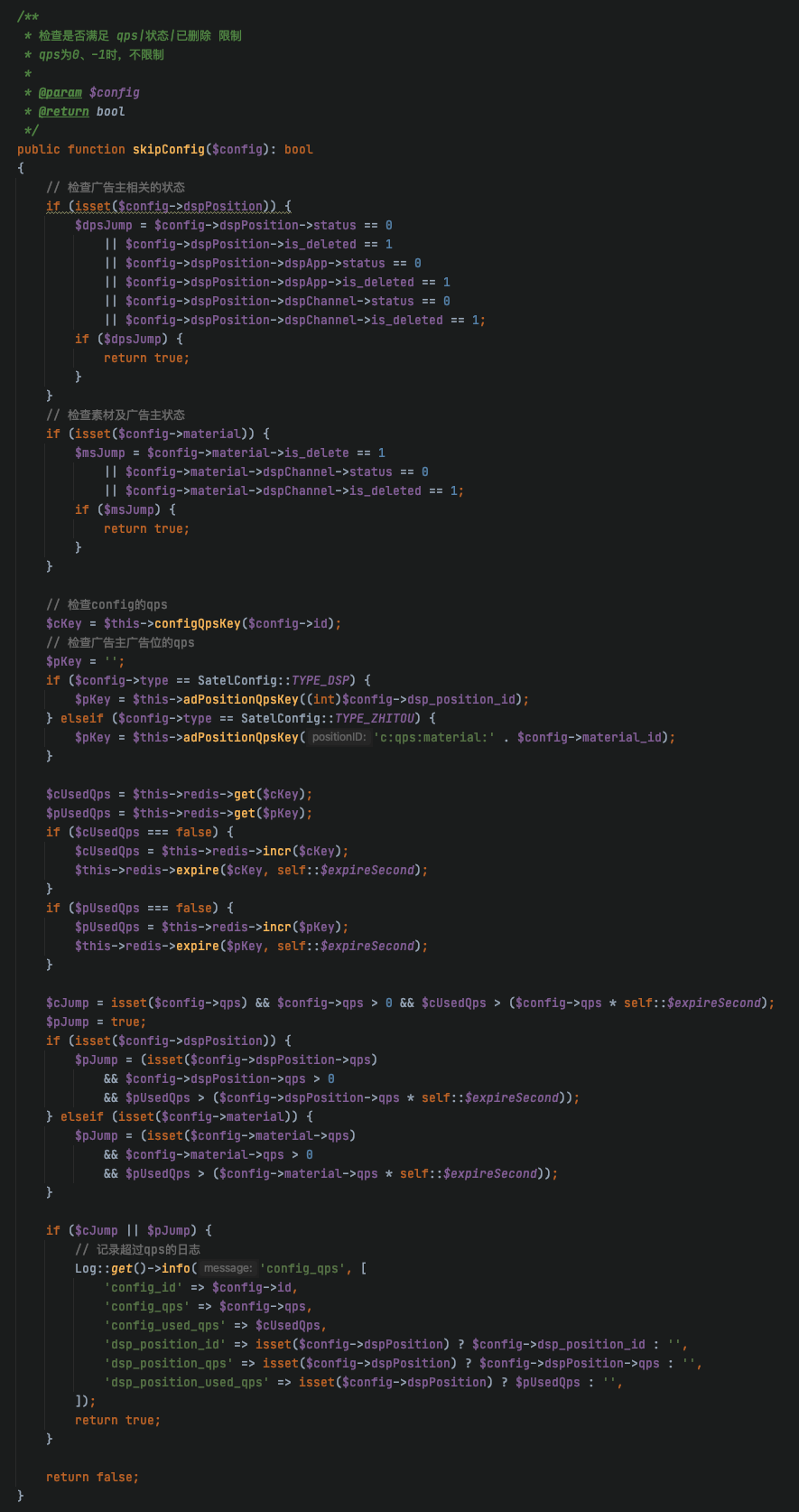
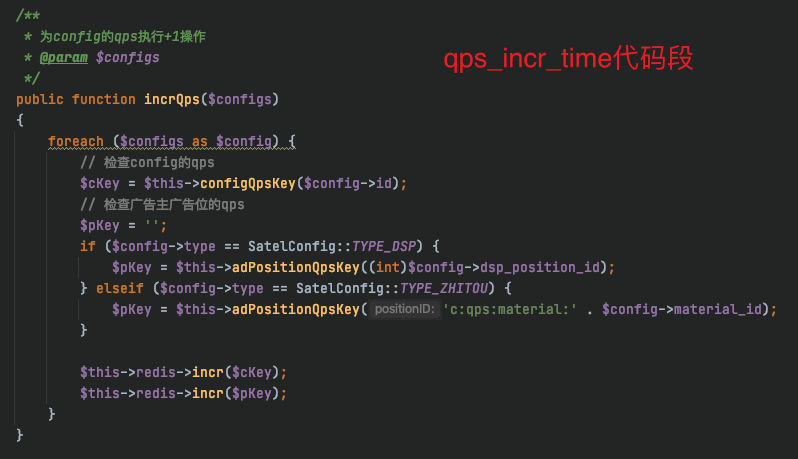
发现 qps 相关的代码段执行时间比较长,下面附上相关代码段

QPS 相关代码段