
这是一个创建于 1678 天前的主题,其中的信息可能已经有所发展或是发生改变。
缘起
Nebula Graph 最早的自动化测试是使用搭建在 Azure 上的 Jenkins,配合着 GitHub 的 Webhook 实现的,在用户提交 Pull Request 时,加个 ready-for-testing 的 label 再评论一句 Jenkins go 就可以自动的运行相应的 UT 测试,效果如下:

因为是租用的 Azure 的云主机,加上 nebula 的编译要求的机器配置较高,而且任务的触发主要集中在白天。所以上述的方案性价比较低,从去年团队就在考虑寻找替代的方案,准备下线 Azure 上的测试机,并且还要能提供多环境的测试方案。
调研了一圈现有的产品主要有:
- TravisCI
- CircleCI
- Azure Pipeline
- Jenkins on k8s (自建)
虽然上面的产品对开源项目有些限制,但整体都还算比较友好。
鉴于之前 GitLab CI 的使用经验,体会到如果能跟 GitHub 深度集成那当然是首选。所谓“深度”表示可以共享 GitHub 的整个开源的生态以及完美的 API 调用(后话)。恰巧 2019,GitHub Action 2.0 横空出世,Nebula Graph 便勇敢的入了坑。
这里简单概述一下我们在使用 GitHub Action 时体会到的优点:
- 免费。开源项目可以免费使用 Action 的所有功能,而且机器配置较高。
- 开源生态好。在整个 CI 的流程里,可以直接使用 GitHub 上的所有开源的 Action,哪怕就是没有满足需求的 Action,自己上手写也不是很麻烦,而且还支持 docker 定制,用 bash 就可以完成一个专属的 Action 。
- 支持多种系统。Windows 、macOS 和 Linux 都可以一键使用,跨平台简单方便。
- 可跟 GitHub 的 API 互动。通过
GITHUB_TOKEN可以直接访问 GitHub API V3,想上传文件,检查 PR 状态,使用 curl 命令即可完成。 - 自托管。只要提供 workflow 的描述文件,将其放置到
.github/workflows/目录下,每次提交便会自动触发执行新的 action run 。 - Workflow 描述文件改为 YAML 格式。目前的描述方式要比 Action 1.0 中的 workflow 文件更加简洁易读。
下面在讲实践之前还是要先讲讲 Nebula Graph 的需求:首要目标比较明确就是自动化测试。
作为数据库产品,测试怎么强调也不为过。Nebula Graph 的测试主要分单元测试和集成测试。用 GitHub Action 其实主要瞄准的是单元测试,然后再给集成测试做些准备,比如 docker 镜像构建和安装程序打包。顺带再解决一下 PM 小姐姐的发布需求,就整个构建起来了第一版的 CI/CD 流程。
PR 测试
Nebula Graph 作为托管在 GitHub 上的开源项目,首先要解决的测试问题就是当贡献者提交了 PR 请求后,如何才能快速地进行变更验证?主要有以下几个方面。
- 符不符合编码规范;
- 能不能在不同系统上都编译通过;
- 单测有没有失败;
- 代码覆盖率有没有下降等。
只有上述的要求全部满足并且有至少两位 reviewer 的同意,变更才能进入主干分支。
借助于 cpplint 或者 clang-format 等开源工具可以比较简单地实现要求 1,如果此要求未通过验证,后面的步骤就自动跳过,不再继续执行。
对于要求 2,我们希望能同时在目前支持的几个系统上运行 Nebula 源码的编译验证。那么像之前在物理机上直接构建的方式就不再可取,毕竟一台物理机的价格已经高昂,何况一台还不足够。为了保证编译环境的一致性,还要尽可能的减少机器的性能损失,最终采用了 docker 的容器化构建方式。再借助 Action 的 matrix 运行策略和对 docker 的支持,还算顺利地将整个流程走通。

运行的大概流程如上图所示,在 vesoft-inc/nebula-dev-docker 项目中维护 nebula 编译环境的 docker 镜像,当编译器或者 thirdparty 依赖升级变更时,自动触发 docker hub 的 Build 任务(见下图)。当新的 Pull Request 提交以后,Action 便会被触发开始拉取最新的编译环境镜像,执行编译。
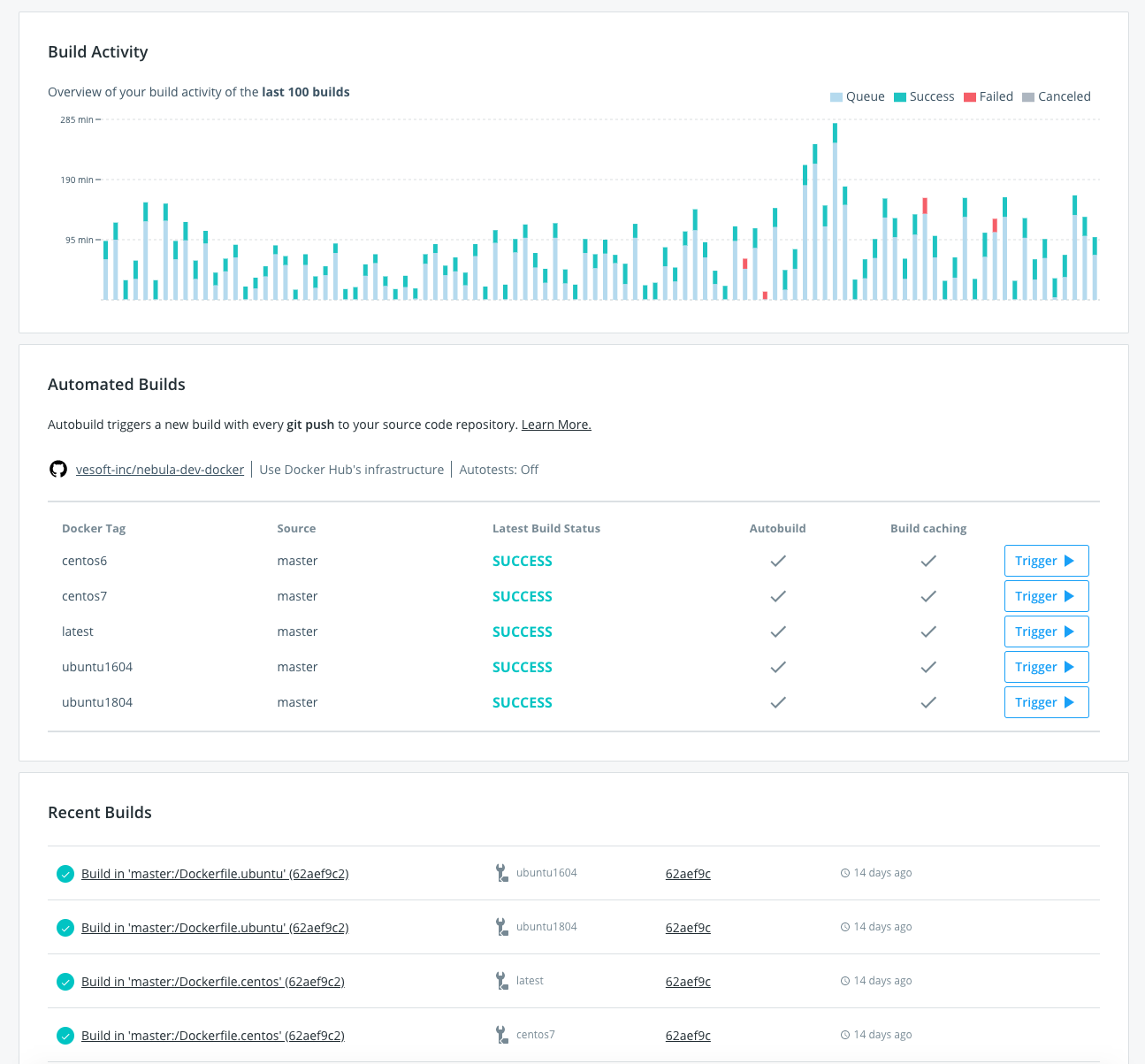
针对 PR 的 workflow 完整描述见文件 pull_request.yaml。同时,考虑到并不是每个人提交的 PR 都需要立即运行 CI 测试,且自建的机器资源有限,对 CI 的触发做了如下限制:
- 只有 lint 校验通过的 PR 才会将后续的 job 下发到自建的 runner,lint 的任务比较轻量,可以使用 GitHub Action 托管的机器来执行,无需占用线下的资源。
- 只有添加了
ready-for-testinglabel 的 PR 才会触发 action 的执行,而 label 的添加有权限的控制。进一步优化 runner 被随意触发的情况。对 label 的限制如下所示:
jobs:
lint:
name: cpplint
if: contains(join(toJson(github.event.pull_request.labels.*.name)), 'ready-for-testing')
在 PR 中执行完成后的效果如下所示:
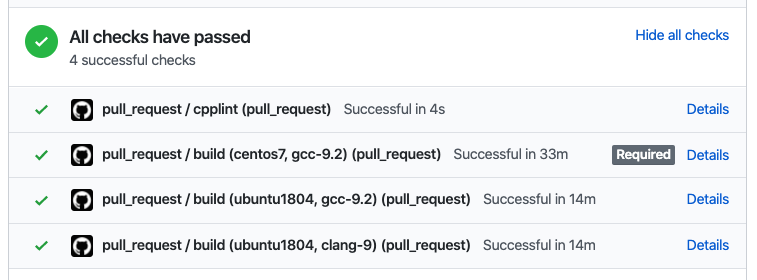
Code Coverage 的说明见博文:图数据库 Nebula Graph 的代码变更测试覆盖率实践。
Nightly 构建
在 Nebula Graph 的集成测试框架中,希望能够在每天晚上对 codebase 中的代码全量跑一遍所有的测试用例。同时有些新的特性,有时也希望能快速地打包交给用户体验使用。这就需要 CI 系统能在每天给出当日代码的 docker 镜像和 rpm/deb 安装包。
GitHub Action 被触发的事件类型除了 pull_request,还可以执行 schedule 类型。schedule 类型的事件可以像 crontab 一样,让用户指定任何重复任务的触发时间,比如每天凌晨两点执行任务如下所示:
on:
schedule:
- cron: '0 18 * * *'
因为 GitHub 采用的是 UTC 时间,所以东八区的凌晨 2 点,就对应到 UTC 的前日 18 时。
docker
每日构建的 docker 镜像需要 push 到 docker hub 上,并打上 nightly 的标签,集成测试的 k8s 集群,将 image 的拉取策略设置为 Always,每日触发便能滚动升级到当日最新进行测试。因为当日的问题目前都会尽量当日解决,便没有再给 nightly 的镜像再额外打一个日期的 tag 。对应的 action 部分如下所示:
- name: Build image
env:
IMAGE_NAME: ${{ secrets.DOCKER_USERNAME }}/nebula-${{ matrix.service }}:nightly
run: |
docker build -t ${IMAGE_NAME} -f docker/Dockerfile.${{ matrix.service }} .
docker push ${IMAGE_NAME}
shell: bash
package
GitHub Action 提供了 artifacts 的功能,可以让用户持久化 workflow 运行过程中的数据,这些数据可以保留 90 天。对于 nightly 版本安装包的存储而言,已经绰绰有余。利用官方提供的 actions/upload-artifact@v1 action,可以方便的将指定目录下的文件上传到 artifacts 。最后 nightly 版本的 nebula 的安装包如下图所示。
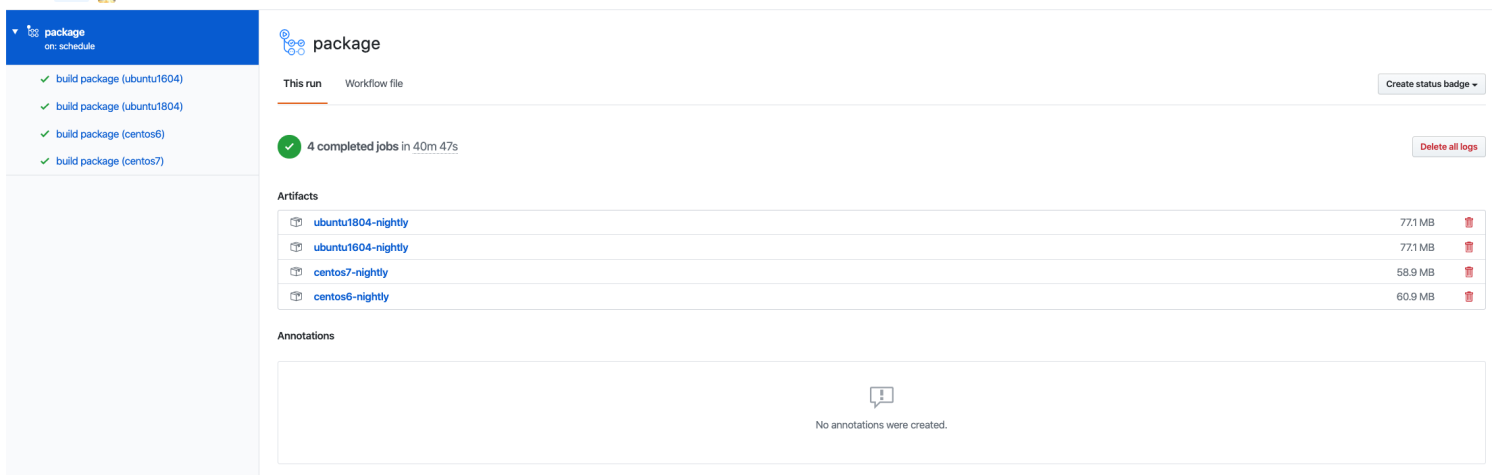
上述完整的 workflow 文件见 package.yaml
分支发布
为了更好地维护每个发布的版本和进行 bugfix,Nebula Graph 采用分支发布的方式。即每次发布之前进行 code freeze,并创建新的 release 分支,在 release 分支上只接受 bugfix,而不进行 feature 的开发。bugfix 还是会在开发分支上提交,最后 cherrypick 到 release 分支。
在每次 release 时,除了 source 外,我们希望能把安装包也追加到 assets 中方便用户直接下载。如果每次都手工上传,既容易出错,也非常耗时。这就比较适合 Action 来自动化这块的工作,而且,打包和上传都走 GitHub 内部网络,速度更快。
在安装包编译好后,通过 curl 命令直接调用 GitHub 的 API,就能上传到 assets 中,具体脚本内容如下所示:
curl --silent \
--request POST \
--url "$upload_url?name=$filename" \
--header "authorization: Bearer $github_token" \
--header "content-type: $content_type" \
--data-binary @"$filepath"
同时,为了安全起见,在每次的安装包发布时,希望可以计算安装包的 checksum 值,并将其一同上传到 assets 中,以便用户下载后进行完整性校验。具体步骤如下所示:
jobs:
package:
name: package and upload release assets
runs-on: ubuntu-latest
strategy:
matrix:
os:
- ubuntu1604
- ubuntu1804
- centos6
- centos7
container:
image: vesoft/nebula-dev:${{ matrix.os }}
steps:
- uses: actions/checkout@v1
- name: package
run: ./package/package.sh
- name: vars
id: vars
env:
CPACK_OUTPUT_DIR: build/cpack_output
SHA_EXT: sha256sum.txt
run: |
tag=$(echo ${{ github.ref }} | rev | cut -d/ -f1 | rev)
cd $CPACK_OUTPUT_DIR
filename=$(find . -type f \( -iname \*.deb -o -iname \*.rpm \) -exec basename {} \;)
sha256sum $filename > $filename.$SHA_EXT
echo "::set-output name=tag::$tag"
echo "::set-output name=filepath::$CPACK_OUTPUT_DIR/$filename"
echo "::set-output name=shafilepath::$CPACK_OUTPUT_DIR/$filename.$SHA_EXT"
shell: bash
- name: upload release asset
run: |
./ci/scripts/upload-github-release-asset.sh github_token=${{ secrets.GITHUB_TOKEN }} repo=${{ github.repository }} tag=${{ steps.vars.outputs.tag }} filepath=${{ steps.vars.outputs.filepath }}
./ci/scripts/upload-github-release-asset.sh github_token=${{ secrets.GITHUB_TOKEN }} repo=${{ github.repository }} tag=${{ steps.vars.outputs.tag }} filepath=${{ steps.vars.outputs.shafilepath }}
上述完整的 workflow 文件见 release.yaml。
命令
GitHub Action 为 workflow 提供了一些命令方便在 shell 中进行调用,来更精细地控制和调试每个步骤的执行。常用的命令如下:
set-output
有时在 job 的 steps 之间需要传递一些结果,这时就可以通过 echo "::set-output name=output_name::output_value" 的命令形式将想要输出的 output_value 值设置到 output_name 变量中。
在接下来的 step 中,可以通过 ${{ steps.step_id.outputs.output_name }} 的方式引用上述的输出值。
上节中上传 asset 的 job 中就使用了上述的方式来传递文件名称。一个步骤可以通过多次执行上述命令来设置多个输出。
set-env
同 set-output 一样,可以为后续的步骤设置环境变量。语法: echo "::set-env name={name}::{value}" 。
add-path
将某路径加入到 PATH 变量中,为后续步骤使用。语法: echo "::add-path::{path}" 。
Self-Hosted Runner
除了 GitHub 官方托管的 runner 之外,Action 还允许使用线下自己的机器作为 Runner 来跑 Action 的 job 。在机器上安装好 Action Runner 之后,按照教程,将其注册到项目后,在 workflow 文件中通过配置 runs-on: self-hosted 即可使用。
self-hosted 的机器可以打上不同的 label,这样便可以通过不同的标签来将任务分发到特定的机器上。比如线下的机器安装有不同的操作系统,那么 job 就可以根据 runs-on 的 label 在特定的机器上运行。 self-hosted 也是一个特定的标签。
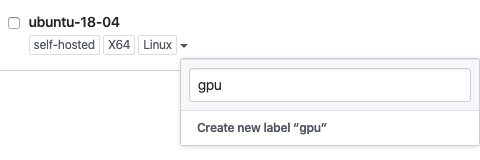
安全
GitHub 官方是不推荐开源项目使用 Self-Hosted 的 runner 的,原因是任何人都可以通过提交 PR 的方式,让 runner 的机器运行危险的代码对其所在的环境进行攻击。
但是 Nebula Graph 的编译需要的存储空间较大,且 GitHub 只能提供 2 核的环境来编译,不得已还是选择了自建 Runner 。考虑到安全的因素,进行了如下方面的安全加固:
虚拟机部署
所有注册到 GitHub Action 的 runner 都是采用虚拟机部署,跟宿主机做好第一层的隔离,也更方便对每个虚拟机做资源分配。一台高配置的宿主机可以分配多个虚拟机让 runner 来并行地跑所有收到的任务。
如果虚拟机出了问题,可以方便地进行环境复原的操作。
网络隔离
将所有 runner 所在的虚拟机隔离在办公网络之外,使其无法直接访问公司内部资源。即便有人通过 PR 提交了恶意代码,也让其无法访问公司内部网络,造成进一步的攻击。
Action 选择
尽量选择大厂和官方发布的 action,如果是使用个人开发者的作品,最好能检视一下其具体实现代码,免得出现网上爆出来的泄漏隐私密钥等事情发生。
比如 GitHub 官方维护的 action 列表:https://github.com/actions。
私钥校验
GitHub Action 会自动校验 PR 中是否使用了一些私钥,除却 GITHUB_TOKEN 之外的其他私钥(通过 ${{ secrets.MY_TOKENS }} 形式引用)均是不可以在 PR 事件触发的相关任务中使用,以防用户通过 PR 的方式私自打印输出窃取密钥。
环境搭建与清理
对于自建的 runner,在不同任务( job )之间做文件共享是方便的,但是最后不要忘记每次在整个 action 执行结束后,清理产生的中间文件,不然这些文件有可能会影响接下来的任务执行和不断地占用磁盘空间。
- name: Cleanup
if: always()
run: rm -rf build
将 step 的运行条件设置为 always() 确保每次任务都要执行该步骤,即便中途出错。
基于 Docker 的 Matrix 并行构建
因为 Nebula Graph 需要在不同的系统上做编译验证,在构建方式上采用了容器的方案,原因是构建时不同环境的隔离简单方便,GitHub Action 可以原生支持基于 docker 的任务。
Action 支持 matrix 策略运行任务的方式,类似于 TravisCI 的 build matrix。通过配置不同系统和编译器的组合,我们可以方便地设置在每个系统下使用 gcc 和 clang 来同时编译 nebula 的源码,如下所示:
jobs:
build:
name: build
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
os:
- centos6
- centos7
- ubuntu1604
- ubuntu1804
compiler:
- gcc-9.2
- clang-9
exclude:
- os: centos7
compiler: clang-9
上述的 strategy 会生成 8 个并行的任务( 4 os x 2 compiler ),每个任务都是( os, compiler )的一个组合。这种类似矩阵的表达方式,可以极大的减少不同纬度上的任务组合的定义。
如果想排除 matrix 中的某个组合,只要将组合的值配置到 exclude 选项下面即可。如果想在任务中访问 matrix 中的值,也只要通过类似 ${{ matrix.os }} 获取上下文变量值的方式拿到。这些方式让你定制自己的任务时都变得十分方便。
运行时容器
我们可以为每个任务指定运行时的一个容器环境,这样该任务下的所有步骤( steps )都会在容器的内部环境中执行。相较于在每个步骤中都套用 docker 命令要简洁明了。
container:
image: vesoft/nebula-dev:${{ matrix.os }}
env:
CCACHE_DIR: /tmp/ccache/${{ matrix.os }}-${{ matrix.compiler }}
对容器的配置,像在 docker compose 中配置 service 一样,可以指定 image/env/ports/volumes/options 等等参数。在 self-hosted 的 runner 中,可以方便地将宿主机上的目录挂载到容器中做文件的共享。
正是基于 Action 上面的容器特性,才方便的在 docker 内做后续编译的缓存加速。
编译加速
Nebula Graph 的源码采用 C++ 编写,整个构建过程时间较长,如果每次 CI 都完全地重新开始,会浪费许多计算资源。因为每台 runner 跑的(容器)任务不定,需要对每个源文件及对应的编译过程进行精准判别才能确认该源文件是否真的被修改。目前使用最新版本的 ccache 来完成缓存的任务。
虽然 GitHub Action 本身提供 cache 的功能,由于 Nebula Graph 目前单元测试的用例采用静态链接,编译后体积较大,超出其可用的配额,遂使用本地缓存的策略。
ccache
ccache 是个编译器的缓存工具,可以有效地加速编译的过程,同时支持 gcc/clang 等编译器。Nebula Graph 使用 C++ 14 标准,低版本的 ccache 在兼容性上有问题,所以在所有的 vesoft/nebula-dev 镜像中都采用手动编译的方式安装。
Nebula Graph 在 cmake 的配置中自动识别是否安装了 ccache,并决定是否对其打开启用。所以只要在容器环境中对 ccache 做些配置即可,比如在 ccache.conf 中配置其最大缓存容量为 1 G,超出后自动替换较旧缓存。
max_size = 1.0G
ccache.conf 配置文件最好放置在缓存目录下,这样 ccache 可方便读取其中内容。
tmpfs
tmpfs 是位于内存或者 swap 分区的临时文件系统,可以有效地缓解磁盘 IO 带来的延迟,因为 self-hosted 的主机内存足够,所以将 ccache 的目录挂载类型改为 tmpfs,来减少 ccache 读写时间。在 docker 中使用 tmpfs 的挂载类型可以参考相应文档。相应的配置参数如下:
env:
CCACHE_DIR: /tmp/ccache/${{ matrix.os }}-${{ matrix.compiler }}
options: --mount type=tmpfs,destination=/tmp/ccache,tmpfs-size=1073741824 -v /tmp/ccache/${{ matrix.os }}-${{ matrix.compiler }}:/tmp/ccache/${{ matrix.os }}-${{ matrix.compiler }}
将所有 ccache 产生的缓存文件,放置到挂载为 tmpfs 类型的目录下。
并行编译
make 本身即支持多个源文件的并行编译,在编译时配置 -j $(nproc) 便可同时启动与核数相同的任务数。在 action 的 steps 中配置如下:
- name: Make
run: cmake --build build/ -j $(nproc)
坑
说了那么多的优点,那有没有不足呢?使用下来主要体会到如下几点:
-
只支持较新版本的系统。很多 Action 是基于较新的 Nodejs 版本开发,没法方便地在类似 CentOS 6 等老版本 docker 容器中直接使用。否则会报 Nodejs 依赖的库文件找不到,从而无法正常启动 action 的执行。因为 Nebula Graph 希望可以支持 CentOS 6,所以在该系统下的任务不得不需要特殊处理。
-
不能方便地进行本地验证。虽然社区有个开源项目 act,但使用下来还是有诸多限制,有时不得不通过在自己仓库中反复提交验证才能确保 action 的修改正确。
-
目前还缺少比较好的指导规范,当定制的任务较多时,总有种在 YAML 配置中写程序的感受。目前的做法主要有以下三种:
- 根据任务拆分配置文件。
- 定制专属 action,通过 GitHub 的 SDK 来实现想要的功能。
- 编写大的 shell 脚本来完成任务内容,在任务中调用该脚本。
目前针对尽量多使用小任务的组合还是使用大任务的方式,社区也没有定论。不过小任务组合的方式可以方便地定位任务失败位置以及确定每步的执行时间。

-
Action 的一些历史记录目前无法清理,如果中途更改了 workflows 的名字,那么老的 check runs 记录还是会一直保留在 Action 页面,影响使用体验。
-
目前还缺少像 GitLab CI 中手动触发 job/task 运行的功能。无法运行中间进行人工干预。
-
action 的开发也在不停的迭代中,有时需要维护一下新版的升级,比如:checkout@v2
不过总体来说,GitHub Action 是一个相对优秀的 CI/CD 系统,毕竟站在 GitLab CI/Travis CI 等前人肩膀上的产品,还是有很多经验可以借鉴使用。
后续
定制 Action
前段时间 docker 发布了自己的第一款 Action,简化用户与 docker 相关的任务。后续,针对 Nebula Graph 的一些 CI/CD 的复杂需求,我们亦会定制一些专属的 action 来给 nebula 的所有 repo 使用。通用的就会创建独立的 repo,发布到 action 市场里,比如追加 assets 到 release 功能。专属的就可以放置 repo 的 .github/actions 目录下。
这样就可以简化 workflows 中的 YAML 配置,只要 use 某个定制 action 即可。灵活性和拓展性都更优。
跟钉钉 /slack 等 IM 集成
通过 GitHub 的 SDK 可以开发复杂的 action 应用,再结合钉钉/slack 等 bot 的定制,可以实现许多自动化的有意思的小应用。比如,当一个 PR 被 2 个以上的 reviewer approve 并且所有的 check runs 都通过,那么就可以向钉钉群里发消息并 @ 一些人让其去 merge 该 PR 。免去了每次都去 PR list 里面 check 每个 PR 状态的辛苦。
当然围绕 GitHub 的周边通过一些 bot 还可以迸发许多有意思的玩法。
One More Thing...
~~图数据库 Nebula Graph 1.0 GA 快要发布啦。欢迎大家来围观。~~
本文中如有任何错误或疏漏欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.com.cn/ 的 建议反馈 分类下提建议 👏;加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot
{kind=link}
作者有话说:Hi,我是 Yee,是图数据 Nebula Graph 研发工程师,对数据库查询引擎有浓厚的兴趣,希望本次的经验分享能给大家带来帮助,如有不当之处也希望能帮忙纠正,谢谢~
 |
1
cosmic 2020-05-08 11:09:31 +08:00 via Android
nice sharing
|
 |
2
xdays 2020-05-08 12:46:34 +08:00
感谢分享!
|
 |
3
salamanderMH 2020-05-08 12:57:53 +08:00
文章好长,之前刚试过 Github Action,挺好用的。
|
 |
4
Hanggi 2020-05-08 13:11:26 +08:00
github action 确实挺不错的,但是对于私有库来说,适合一些小的集成测试和部署(例如 github page),如果你的测试量比较大的话可能测试余额会不够用。
建议试试基于 Docker 的自建集成测试部署环境。 [Drone 基于 Docker 的集成测试部署]( https://hanggi.me/post/deployment/drone-ci/) 如果有 k8s 环境也可以部署到 k8s [在 k8s 上搭建 Drone 集成测试部署]( https://hanggi.me/post/deployment/drone-ci-k8s/) |
 |
5
NebulaGraph OP @Hanggi 私有仓的确是有这些限制,但是如果是开源的话,是没有这种限制的
|
 |
6
ryh 2020-05-08 13:53:35 +08:00
没有找到好用的 upload to release, 官方的 action 必须要 create 里生成的 upload_url , 不然只有自己拼 upload_url
要用 api 去取 release id 再取 upload_url, 第三方的更没有好用的 |
 |
7
zzl22100048 2020-05-08 20:18:03 +08:00 via iPhone
NebulaGraph 图库好用不,10 亿节点,百亿边大概要什么配置呢
|
|
8
NebulaGraph OP @zzl22100048
硬盘: - 点的数据量: 比如 1 亿个点,每个点的属性为 1k,需要 100 G 存储数据空间(属性会做压缩,但是压缩比是不定的,会根据你的数据类型不同的变化,假如是无属性的点,就不会压缩) - 边的数据量: 比如 10 亿条边,每条边的属性为 1k,需要 1t 存储数据空间,插入的时候时候正反向都会插入,所以这里是 2t space 的 parttion 数量: 假如 space 的 partion 数量为 100, 那么 wal 日志空间大小就需要 16 * 1024 * 1024(wal_file_size) * 100 = 1600 M 副本数量: 副本数据为 3 的话 假如是三副本的集群,那么存完这么多数据,需要的硬盘空间为每台 2.1t ,插入过程假如 wal 没能及时删除,可以也大于需要 1.1t ,(现在默认是 4 个小时会删除,看插入的速度) cpu: 现在 query engine 是会将所在机子的所有线程使用上 现在 storage 用的 cpu 数最大是 16 个, 参数是 num_io_threads, 每个线程的 work 数为 num_worker_threads 内存: storage: rocksdb: rocksdb_block_cache 为 1024 m,即 1G vertex cache: 默认最大缓存这么多个点 16 * 1000 * 1000 ( vertex_cache_num ), 假如按照上面每个点为 1k,这里需要 16 G wal_buffer_size: 8 * 1024 * 1024 *2 = 16 M 最少需要 17G, 加上程序运行需要的其他内存,用户根据自己的业务应用进行预留。最好 50G 以上,但是根据业务应用调整。 graph: 根据业务配置,假如会查询大量的数据,需要配置大点的内存 综上所述,一个要导入 1 亿个点(每个点的属性为 1k ),10 亿条边,(每条边的属性为 1k ),创建的 space 为 3 副本,100 个 partion, 最大需要硬盘容量为 4.2t * 3 = 12.6t (没压缩的情况) 稳定后的,需要的硬盘容量为 2.1 * 3 = 6.3t (按压缩比 5 ~ 20 ),按最小的压缩比可以到 1.26 t 内存是,存储服务器,最好配置 50 G 以上,query engine 根据业务应用,最好可以配置大点内存 |
|
9
NebulaGraph OP @zzl22100048 数据导入有个小 Tips:导入的历史数据会占空间,多次导入的话,最好清理一下。
|