
ACG2vec 系列之 Pix2Score——基于深度学习的动漫插图打分模型
简介
在线体验: https://cheerfun.dev/acg2vec/#Pix2Score
github 主仓库地址( tensorflow 的 savemodel 格式可以在 release 中下载): https://github.com/OysterQAQ/ACG2vec (求 star ~)
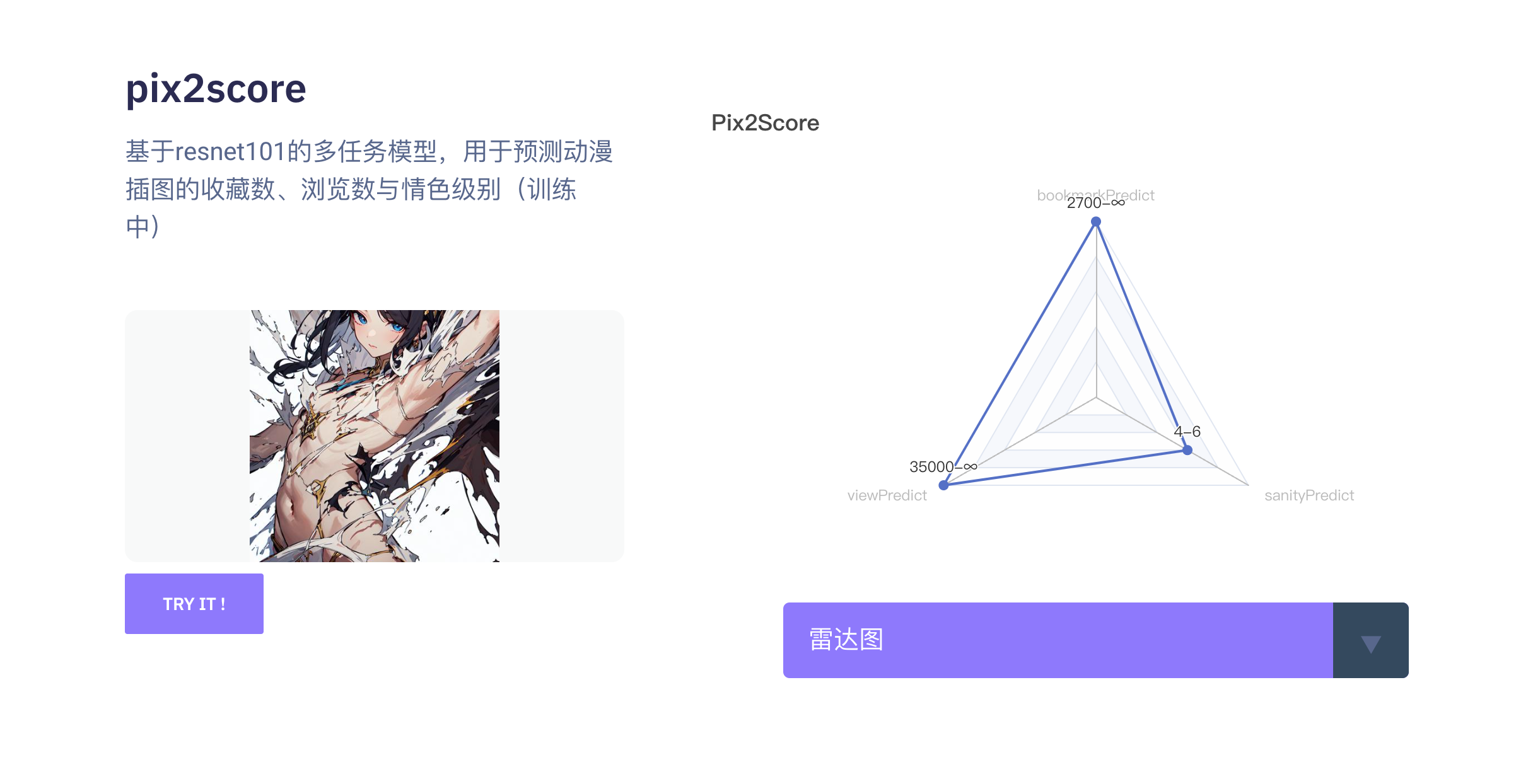
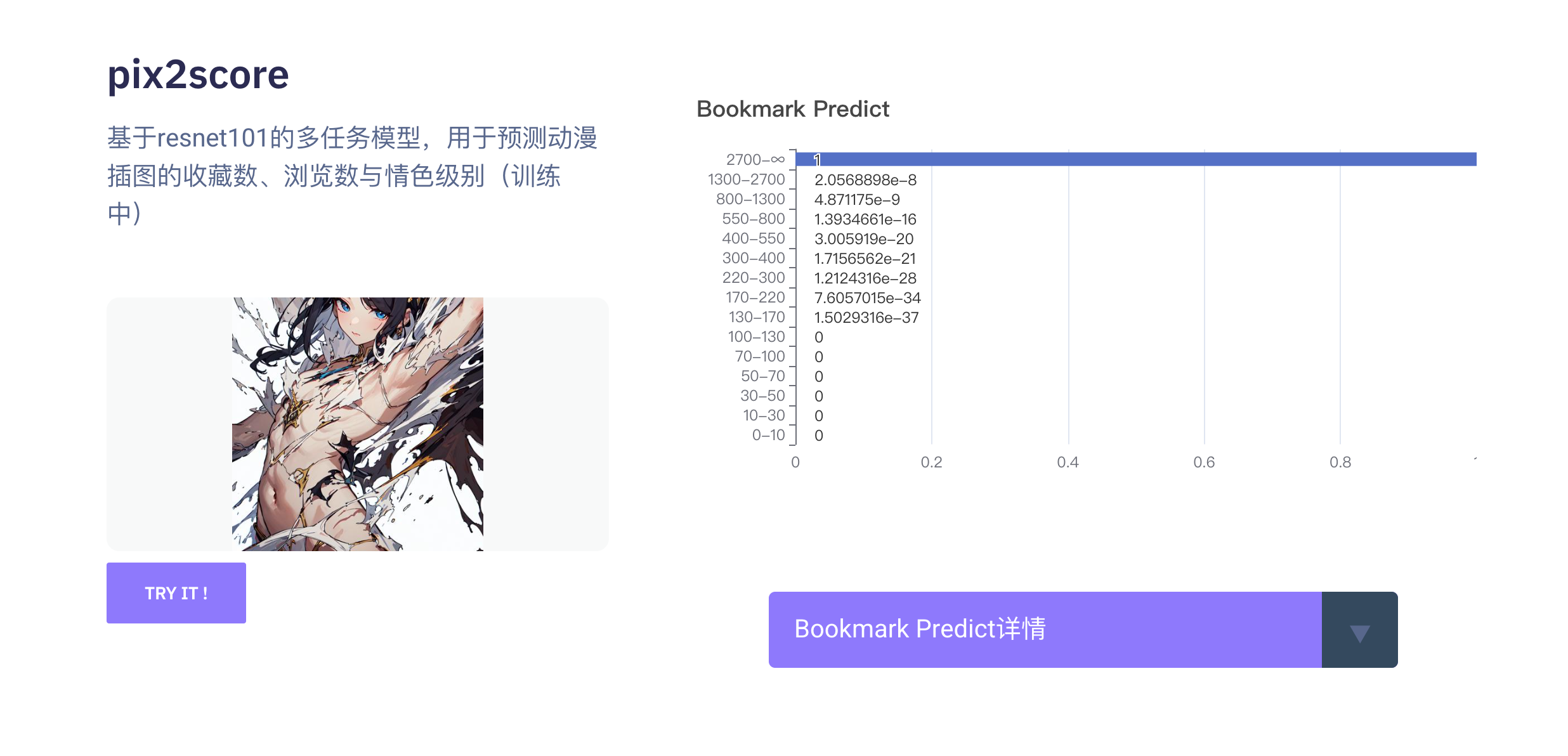
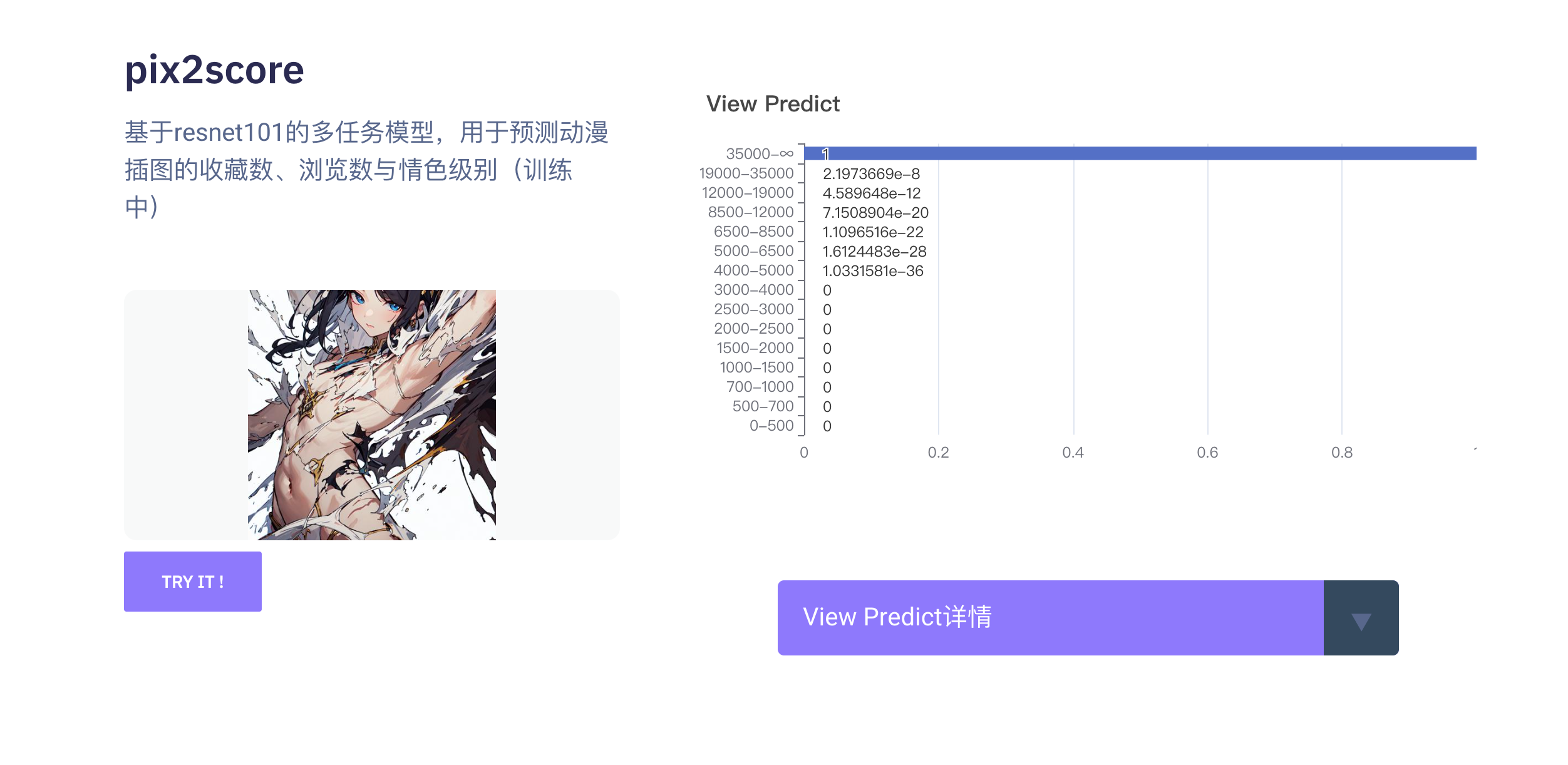
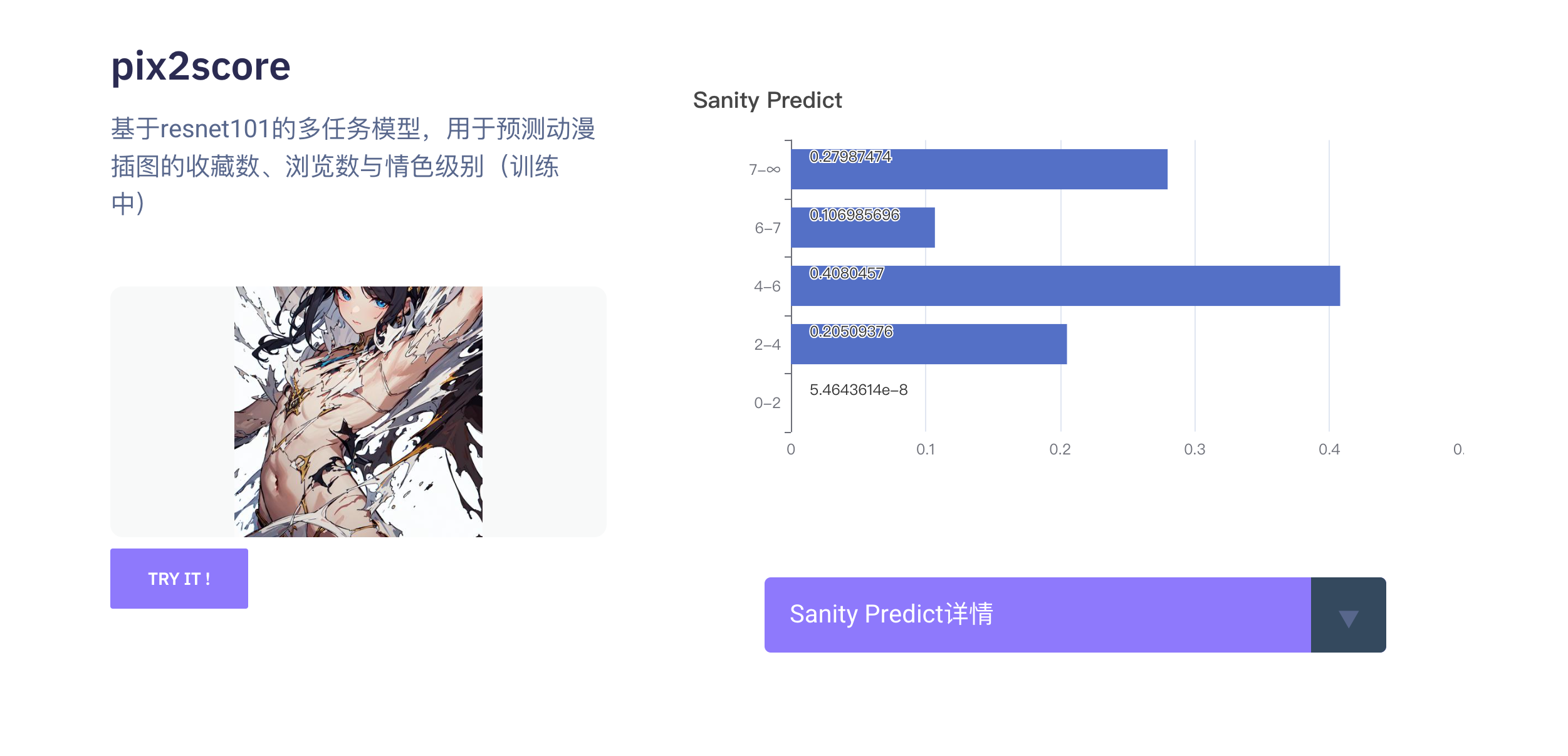
基于resnet101对插画的浏览数、收藏数、情色级别的分类预测,以 1e-3 的学习率在动漫插画数据集下进行训练,输入尺寸为 224x224 ,输出字典为
{
"bookmark_predict": {
"0": "0-10",
"1": "10-30",
"2": "30-50",
"3": "50-70",
"4": "70-100",
"5": "100-130",
"6": "130-170",
"7": "170-220",
"8": "220-300",
"9": "300-400",
"10": "400-550",
"11": "550-800",
"12": "800-1300",
"13": "1300-2700",
"14": "2700-∞"
},
"view_predict": {
"0": "0-500",
"1": "500-700",
"2": "700-1000",
"3": "1000-1500",
"4": "1500-2000",
"5": "2000-2500",
"6": "2500-3000",
"7": "3000-4000",
"8": "4000-5000",
"9": "5000-6500",
"10": "6500-8500",
"11": "8500-12000",
"12": "12000-19000",
"13": "19000-35000",
"14": "35000-∞"
},
"sanity_predict": {
"0": "0-2",
"1": "2-4",
"2": "4-6",
"3": "6-7",
"4": "7-∞"
}
}
预览
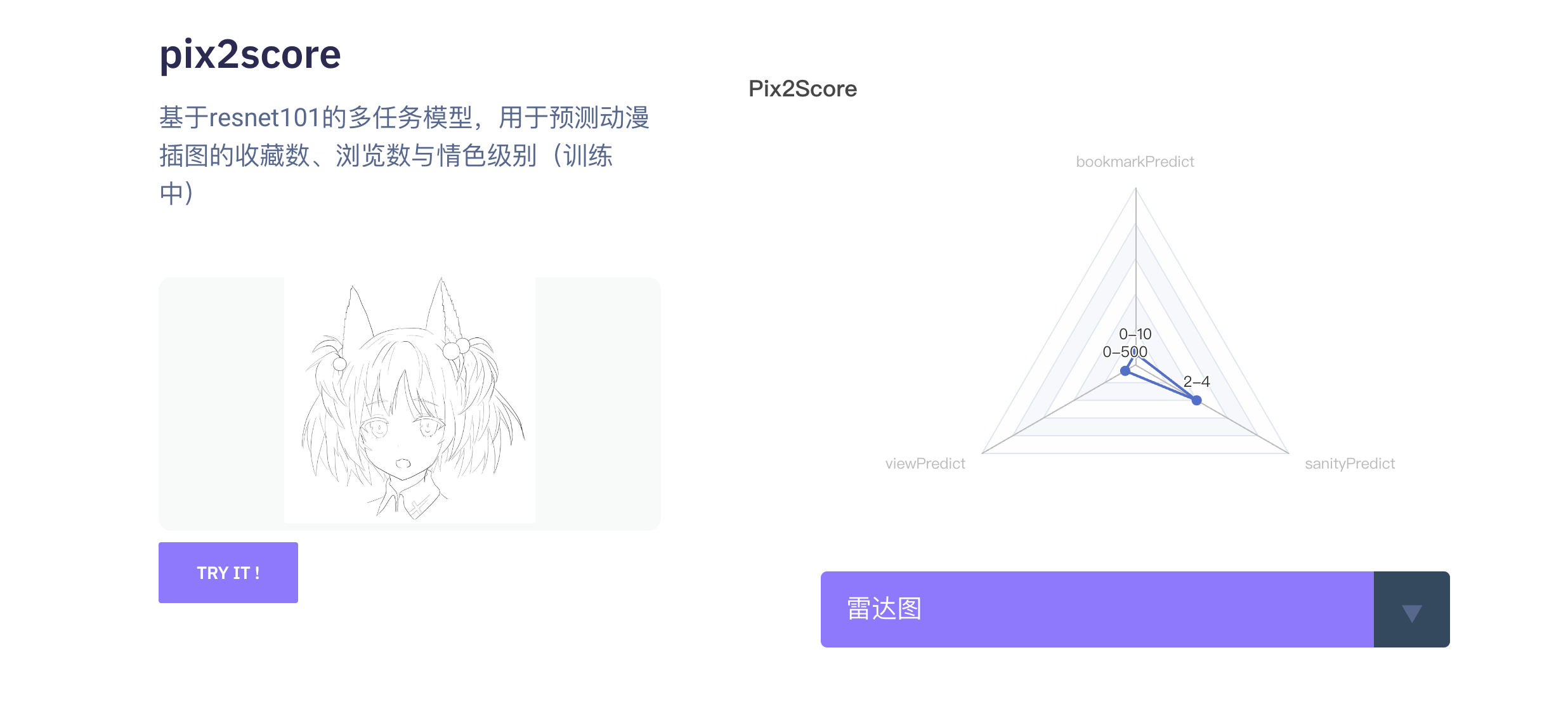
项目过程中解决的问题
- 样本类别比例失衡 将元数据导入 clickhouse 查找 n 分位数来重新划分分段范围
- 数据集过大 无法一次读入内存,使用 generator 逐步读取
- 训练链路中 io 瓶颈 取数据与预处理数据造成瓶颈,将 dataset 导出成 tfrecord 二进制格式(实测可以跑满机械硬盘连续读写值,大概是 250M/s )
- 开启混合精度导致 loss nan 调整学习率
- 多任务梯度带偏 多任务存在简单任务与复杂任务,学习到后期,网络中的权重更新的梯度被困难任务 loss 和简单任务 loss 的加和共同所影响,为了维持简单任务的 loss 会导致复杂任务 loss 下降缓慢,后期通过手动调整 loss 权重得到改善,也实现了 pcgrad 但是没有什么改善
- 模型训练正常推理输出 nan 排查出 bn 层 moving_mean 与 moving_variance 权重异常(这也是为什么训练正常推理异常的原因),重新使用对应层初始化器初始化异常权重后,继续训练(之前训练拟合进度慢的问题也和这个有关),出现 nan 权重大概是因为混合精度造成的,详见 https://oysterqaq.com/archives/1463
- 部署的预处理一致性 在模型本体集成 base64 图片预处理层,无需顾虑预处理行为( resize )不同导致的推理结果差异


