
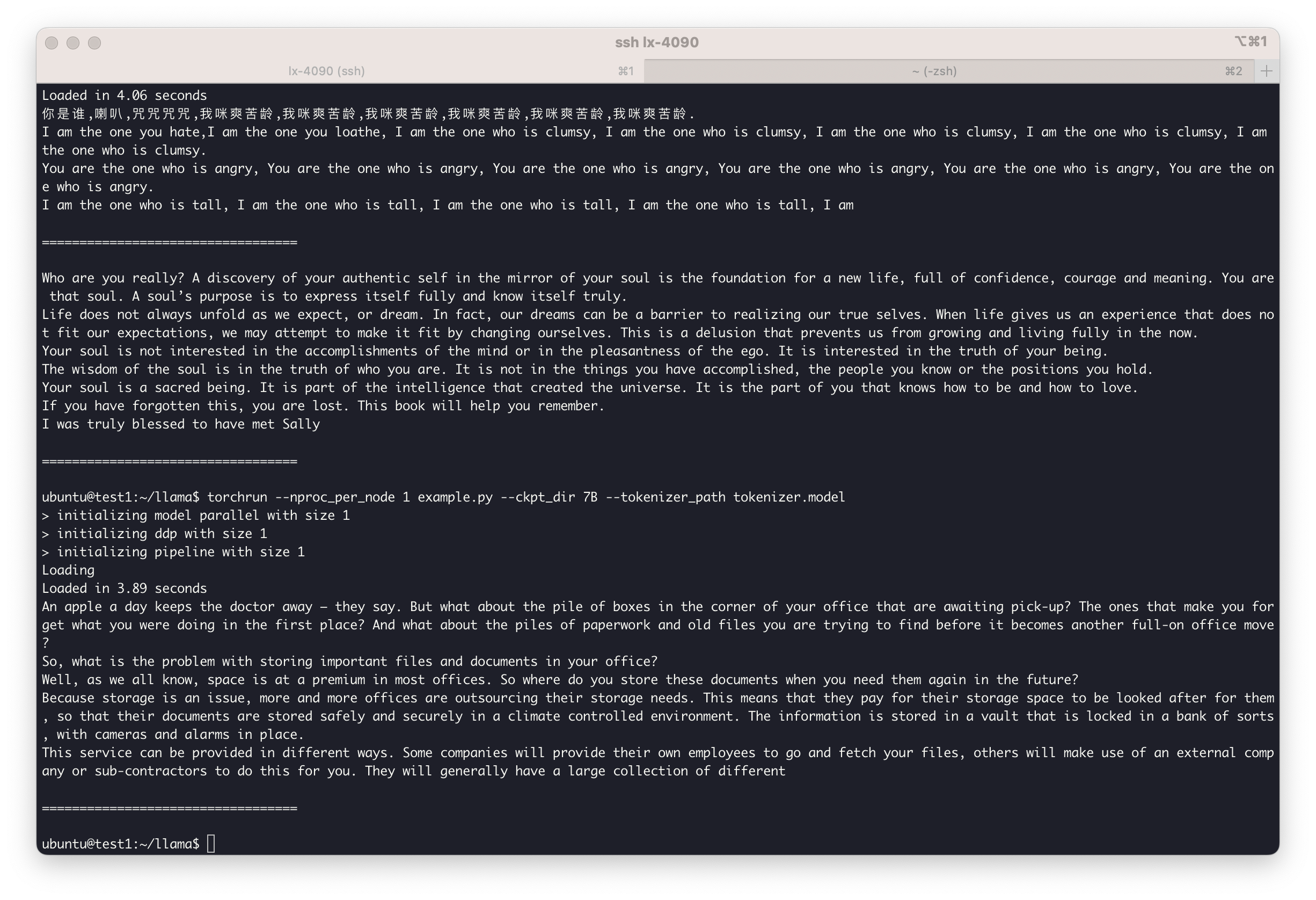
相信大家都已经下载了 LLaMA 的模型来玩了,我今天也玩了一下,效果其实和想象的差很多。
运行环境: GPU: RTX 4090 Weight: LLaMA-7B 在默认 FP16 下运行,会占用 22GB 左右的显存
总结:英文补全勉强能看,但好像还是挺差的,中文补全直接胡言乱语,和 GPT-3 相距甚远,可能还要作为模型基础继续针对训练,对普通用户来说基本没什么可用性,毕竟有一张至少 24G VRAM 的 GPU 就挺难了

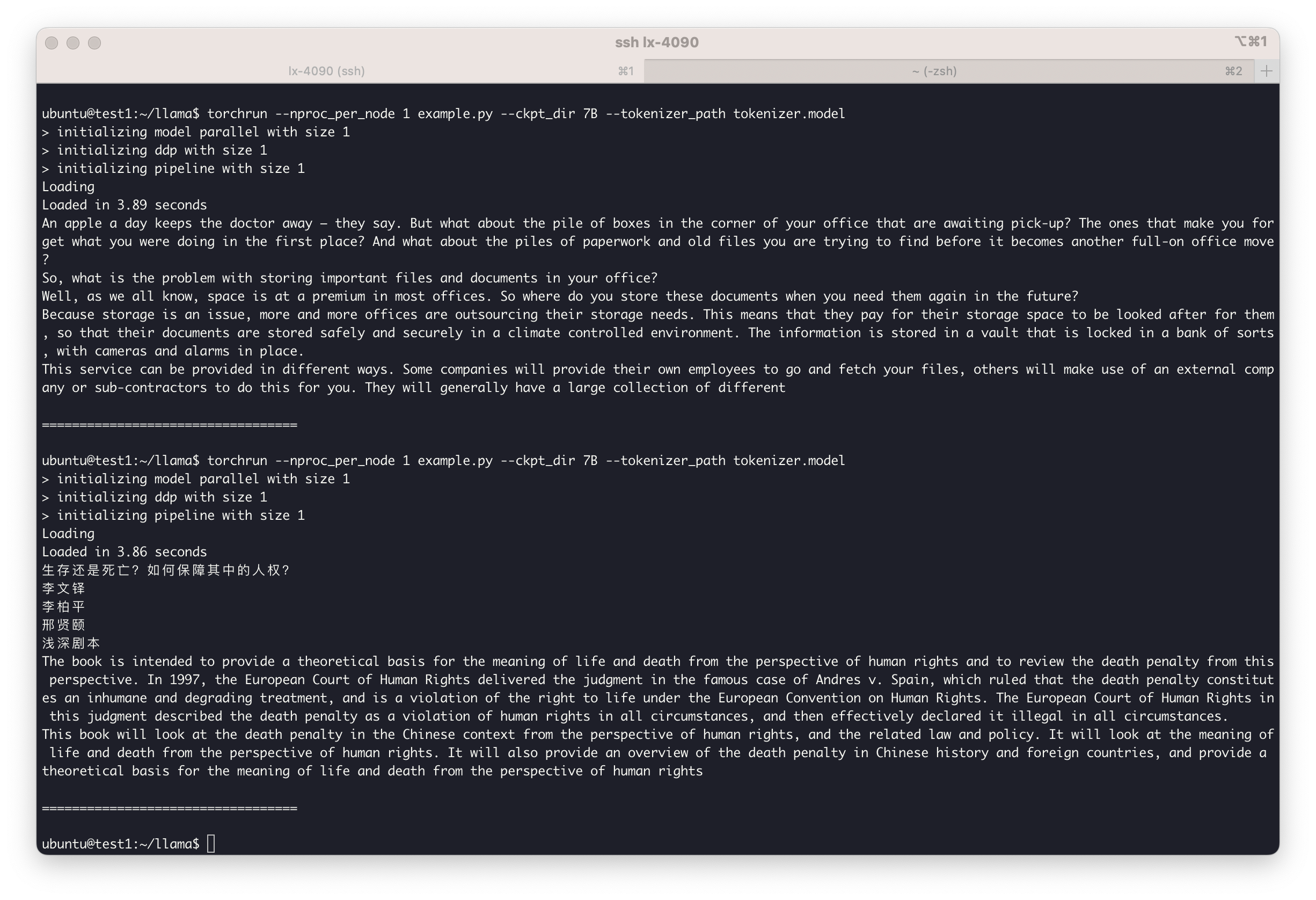
相信大家都已经下载了 LLaMA 的模型来玩了,我今天也玩了一下,效果其实和想象的差很多。
运行环境: GPU: RTX 4090 Weight: LLaMA-7B 在默认 FP16 下运行,会占用 22GB 左右的显存
总结:英文补全勉强能看,但好像还是挺差的,中文补全直接胡言乱语,和 GPT-3 相距甚远,可能还要作为模型基础继续针对训练,对普通用户来说基本没什么可用性,毕竟有一张至少 24G VRAM 的 GPU 就挺难了
 |
1
Wenbobobo Mar 5, 2023 via Android
|
 |
2
yzlnew Mar 9, 2023 via Android
你跑一个 7B 的怎么可能会行啊?
|
 |
5
18601294989 Apr 12, 2023
13b 啊
|
