
作者:陈其友 | 旷视 MegEngine 架构师
MegPeak 介绍
在这个算力需求爆炸的大背景下,如何发挥出已有硬件的最大算力变得非常重要,直观一点是:我们需要对现有算法针对特定的处理器进行极致的性能优化,尽量满足目前 AI 算法对算力高要求。为了能够做到极致的性能优化,我们可能的方向有:
- 优化算法,使得算法能够在满足准确度前提下,访存和计算量尽量小
- 优化程序,使得实现这些算法的程序最大限度发挥处理器性能
在优化程序的过程中,首先要解决的问题是:如何评估我们程序发挥了处理器几成的算力,以及进一步优化空间和优化方向。
为了更懂我们的处理器,MegEngine 团队开发了一个工具 MegPeak,可以帮助开发人员进行性能评估,开发指导等,目前已经开源到 GitHub。
MegPeak 功能
通过 MegPeak 用户可以测试目标处理器:
- 指令的峰值带宽
- 指令延迟
- 内存峰值带宽
- 任意指令组合峰值带宽
虽然上面的部分信息可以通过芯片的数据手册查询相关数据,然后结合理论计算得到,但是很多情况下无法获取目标处理器详尽的性能文档,另外通过 MegPeak 进行测量更直接和准确,并且可以测试特定指令组合的峰值带宽。
MegPeak 使用方法
使用方法参考 MegPeak 的 Readme 文档
MegPeak 使用示例
测试 ArmV8 上通用指令峰值和延迟,编译完成之后,在目标处理器上执行 megpeak ,得到:
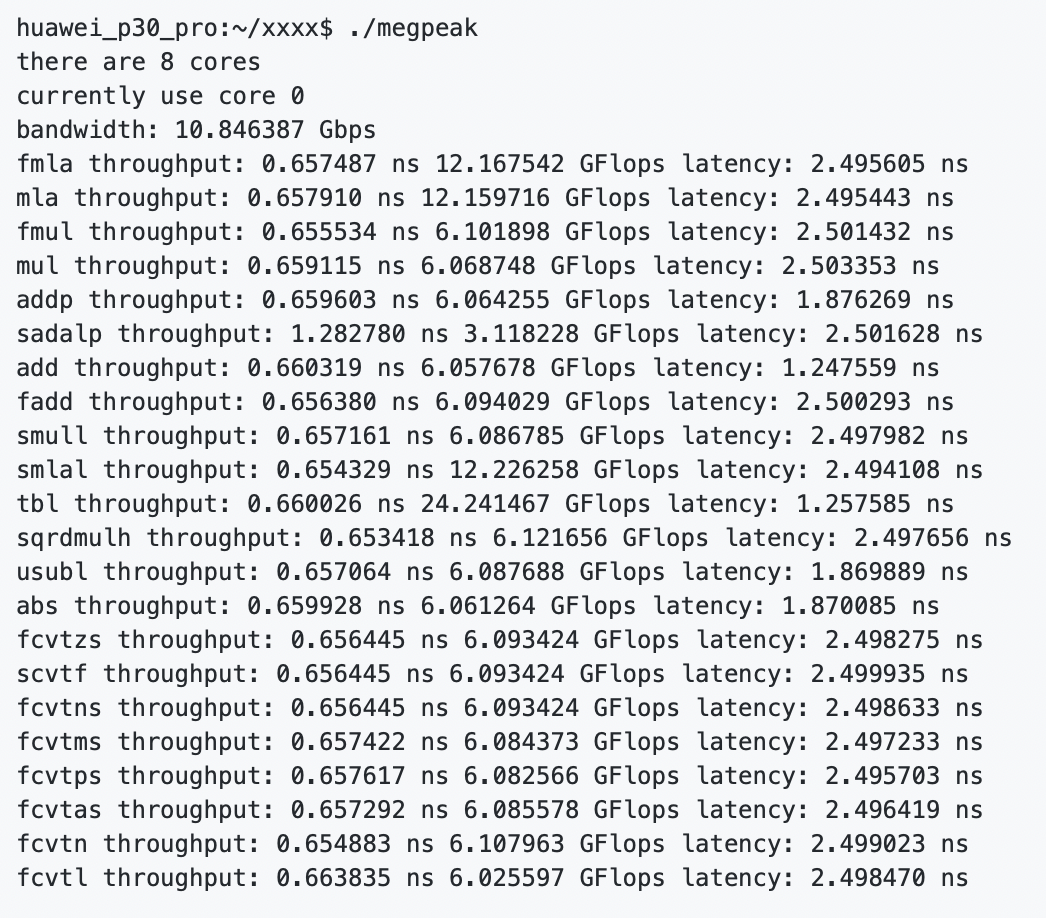
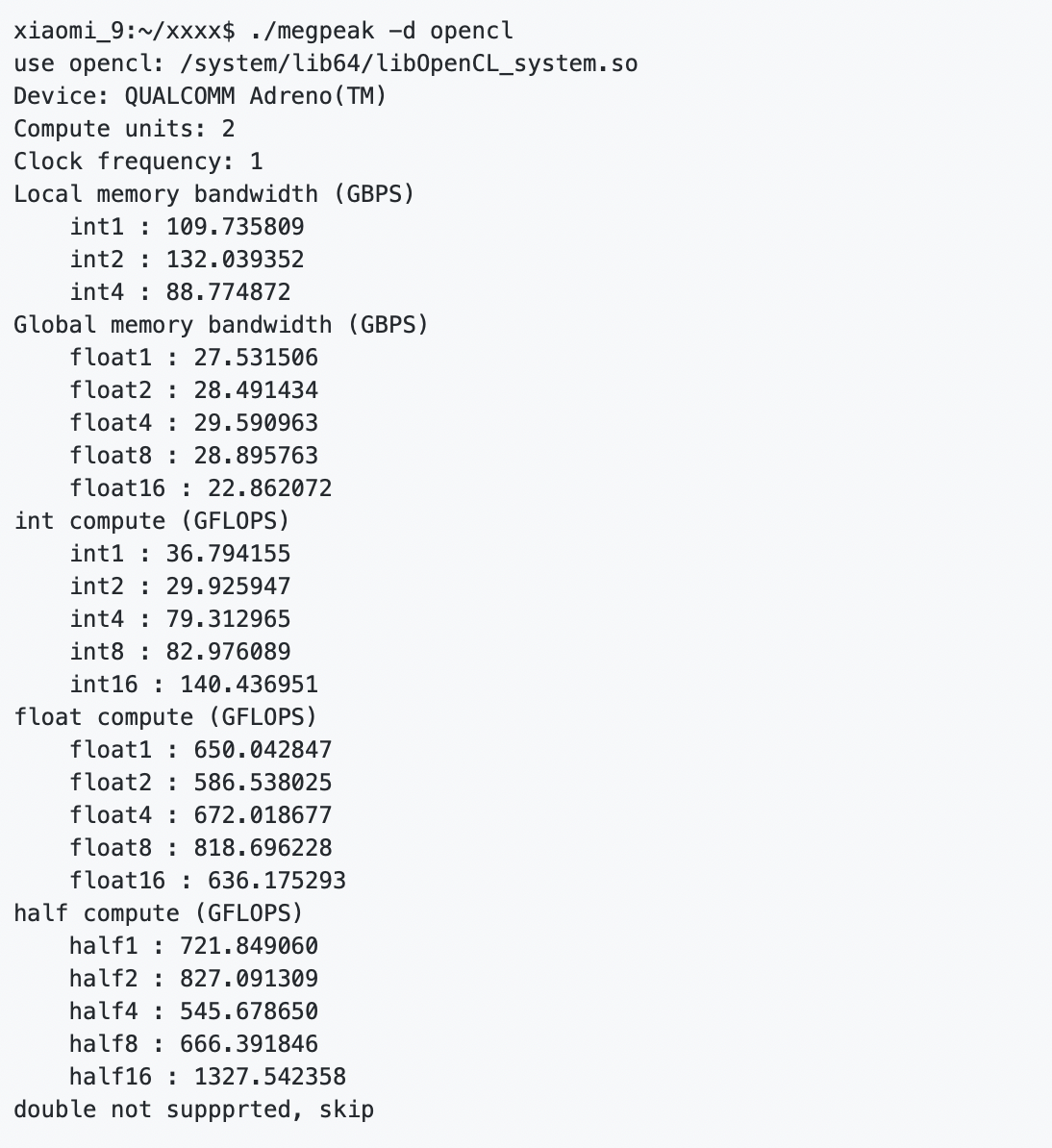
如上图所示,MegPeak 可以精确测试出 CPU 上每条指令的计算峰值以及延迟周期。OpenCL 上将测试出不同数据类型进行访存的 Local Memory ,Global Memory 的带宽,以及 int/float 不同数据类型进行计算的峰值。这些数值将有效的指导我们评估目前程序的性能,并绘制 RoofLine ,将可以帮助用户诊断出阻塞程序主要因素,是访存或者计算,具体使用分析方法将在后面介绍。
MegPeak 原理
MegPeak 测试的主要参数是
- CPU 不同指令的计算峰值,以及指令延迟,以及内存带宽
- OpenCL 中不同内存的数据访存带宽,以及不同计算数据类型的计算峰值
要了解 MegPeak 是如何测试出上面这些性能数据,并且做到和数据手册上查询到尽量一致,因此需要读者了解下面 CPU 流水线相关细节。
处理器流水线
现代处理器为了增加指令的吞吐,引入了指令流水线,指令流水线可以将一条指令的执行过程划分为多个阶段,经典的 5 级流水线有:取指令,翻译指令,执行指令,访问寄存器,写回数据,这 5 个阶段,处理器中执行每个阶段的物理单元独立,因此理想状态下,每个时钟周期每个阶段对应的物理单元都能执行一次对应的操作,这样就形成了流水线,这样处理器每个时钟周期就可以完成执行一条指令。如下表所示,从第 5 个时钟周期之后,每个时钟周期都会完成一条指令执行:
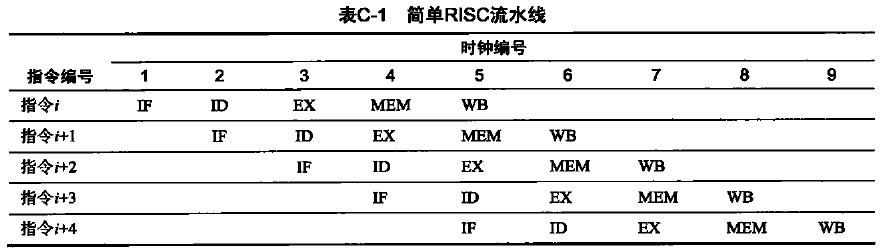
但是,流水线在实际执行时候不可能一直这样流畅的执行下去,会存在以下的冒险,阻塞流水线。
- 结构冒险——如果硬件无法同时支持指令的所有可能组合方式,就会出现资源冲突,从而导致结构冒险
- 数据冒险——流水线指令存在先后顺序,如果一条指令取决于先前指令的结果,就可能导致数据冒险
- 控制冒险——分支指令及其他改变程序计数器的指令实现流水化时,可能导致控制冒险
MegPeak 中测量处理器指令的计算峰值和延迟就是通过控制指令间的数据冒险,尽可能排除结构冒险和控制冒险来实现的,因为 MegPeak 中需要通过写 Code 来控制处理器的数据冒险,为了排除编译器编译 code 时候的优化带来的干扰,所以在 MegPeak 在测试中的核心代码使用汇编来实现的。
测试指令峰值
为了测量处理器上一条指令的计算峰值,我们需要写出重复执行这条指令,但是没有任何冒险的代码,所以需要代码控制数据冒险和控制冒险。
-
消除数据冒险----消除重复指令之间的数据依赖,让前后指令之间没有下面的数据相关,虽然 WAW ,WRA 不是真正的数据相关,处理器可能会使用寄存器重命名来解决,但是我们还是尽量不要写出这样的数据相关。
- 写后读( RAW ):上一条指令写入,下一条指令读取写入数据,这时候后一条指令需要等上一条指令运行结束之后再运行
- 写后写( WAW ):两条指令前后写入同一个寄存器,这时候数据写入的先后顺序很重要
- 读后写( WRA ) :上一条指令读取一个寄存器,下一条指令将新的数据写入这个寄存器,他们的顺序也同样很重要
- 尽可能的消除控制冒险----为了重复多次执行同一条指令,我们可能会用循环来实现,但是循环里面有分支,可能会造成控制冒险,所以我们需要尽可能的循环展开,让一个循环里面执行更多的数据无关的指令,但是这个数量会被处理器的寄存器数量限制。
下面是 MegPeak 测试 Arm64 上 fmla 指令计算峰值时候的核心 Code 。
static int fmla_throughput() {
asm volatile(
"eor v0.16b, v0.16b, v0.16b\n"
"eor v1.16b, v1.16b, v1.16b\n"
...
"eor v19.16b, v19.16b, v19.16b\n"
"mov x0, #0\n"
"1:\n"
"fmla v0.4s, v0.4s, v0.4s\n"
"fmla v1.4s, v1.4s, v1.4s\n"
...
"fmla v19.4s, v19.4s, v19.4s\n"
"add x0, x0, #1 \n"
"cmp x0, %x[RUNS] \n"
"blt 1b \n"
:
: [RUNS] "r"(megpeak::RUNS)
: "cc", "v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7", "v8", "v9", "v10", "v11", "v12", "v13",
"v14", "v15", "v16", "v17", "v18", "v19", "x0");
return megpeak::RUNS * 20;
}
上面的内嵌汇编代码中,主要做了几件事情
- 初始化 0–19 号 neon 寄存器为零,这一步不是必须的,但可以避免计算过程中出现 nan 导致的潜在影响。
- 创建主循环,主循环中每条指令执行,从对应的寄存器读取数据,并执行 fmla 指令,将计算结果写到相同的寄存器中,同一条指令内部没有数据相关。
这里有一个问题需要解释,为什么选择 20 个寄存器:
- 如果寄存器选择太少,上一次循环可能还没有计算完成,下一次循环读取相同的寄存器,可能造成数据相关,因此循环里面执行的指令条数需要大于指令延迟和处理器单个周期内能够执行的指令数的乘积,但是我们不知道这条指令延迟,但是可以估计,除了特殊的指令,延迟一般不超过 10 个时钟周期。
- Arm64 有 32 个 neon 寄存器,为什么不选择 32 个寄存器,因为 20 个寄存器已经可以避免数据和控制相关了,测试发现使用更多的寄存器影响很小。 执行上面的代码,可以统计执行的时间,加上可以提前通过指令的数目以及循环的次数计算出真正的计算量,因此便可以计算出指令的计算峰值。
测试指令延迟
为了测量处理器上一条指令的执行延迟,我们需要写出重复执行这条指令,并让这些指令之间存在严格的数据冒险,尽量排除其他冒险。
- 制造数据冒险----让前后两条指令之间的数据存在真正的数据依赖( RAW ),即上一条指令的输出为下一条指令的输入
- 尽可能的消除控制冒险----同上
下面是 MegPeak 测试 Arm64 上 fmla 指令延迟的核心 Code 。
static int fmla_latency() {
asm volatile(
"eor v0.16b, v0.16b, v0.16b\n"
"mov x0, #0\n"
"1:\n"
"fmla v0.4s, v0.4s, v0.4s\n"
//重复 20 次
...
"fmla v0.4s, v0.4s, v0.4s\n"
"add x0, x0, #1 \n"
"cmp x0, %x[RUNS] \n"
"blt 1b \n"
:
: [RUNS] "r"(megpeak::RUNS)
: "cc", "v0", "x0"
);
return megpeak::RUNS * 20;
}
上面的内嵌汇编代码中,主要将 fmla v0.4s, v0.4s, v0.4s\n 这条指令重复了 20 次,这样每条指令都依赖上一条指令的计算结果,所以存在严格的数据相关。
执行代码,统计执行时间,通过执行的指令条数,可以计算出这条指令最终的延迟。
上面的代码在 MegPeak 中实现,不是这么直接,而是通过宏来实现 code 的生成。
用 MegPeak 测到的数据,可以用来干什么
MegPeak 可以测试出处理器的内存带宽,指令的理论计算峰值,指令的延迟等信息,因此可以帮助我们:
- 绘制 Roofline Model 指导我们优化模型性能
- 评估程序的优化空间
- 探索指令组合的理论计算峰值
另外 MegPeak 还可以提供对理论的验证,如我们通过处理器频率单核单周期指令发射数量每条指令执行的计算量可以计算出理论计算峰值,然后我们可以通过 MegPeak 进行实际测量进行验证。
绘制指令相关的 Roofline Model

Roofline 模型被大量的使用在高性能计算中,是评估算法的可优化程度和优化方向的重要工具。使用 MegPeak 可以绘制出更加具体的关于指令对应的 Roofline 模型,如:在 CPU 中,不同的数据类型,虽然访存带宽不会改变,但是计算峰值差距比较大,比如在 arm 上 float 的计算峰值和 int8 的计算峰值差距很大。
评估代码优化空间
在优化具体算法的时候,可以通过 MegPeak 测试出 kernel 里面的主要指令的最大峰值,如在 Arm 上优化 fp32 Matmul 的时候,主要用到的指令是 fmla 指令,这时候可以测试程序实际运行的峰值,如果指令的峰值和程序的峰值差距越小,说明代码优化的越好。
另外,可以根据算法实现计算出计算量和访存量,并使用 MegPeak 绘制出上面的 Roofline ,通过计算实际的计算密度,然后再对应到 Roofline 中,如果计算密度落在上图中的绿色区域,说明程序需要更多考虑优化访存,提供更优的访存模型,如分块,提前 pack 数据等。如果计算强度的点落在灰色区域说明,代码已经最优了,如果还想进一步提速,只能考虑从算法角度进行优化了,如:在卷积中使用 FFT,Winograd 等算法进行优化。
探索最优指令组合
很多 Kernel 的优化不是单纯的某一条指令就可以衡量,可能需要多条指令的组合才能代表整个 Kernel 的计算,因此我们需要探索如何组织这些指令使其达到处理器最优的性能。下面列举在 A53 小核优化 fp32 Matmul 的过程中,由于 Matmul 是计算密集型算子,考虑通过多发射隐藏访存指令的开销,使用 MegPeak 配合进行分析,探索如何组合指令实现尽可能多的多发射。
因为小核上面资源有限,指令多发射有很多限制,
- 首先使用 MegPeak 出测试 A53 上 fp32 的 fmla 指令的计算峰值,将其定义为 100% 峰值计算性能
-
测试哪些指令组合可以支持双发射
- 在 MegPeak 中添加 vector load 和 fmla 1:1 组合的代码,然后测试其峰值仅仅为 float 峰值的 36%,表明 Vector load 和 fmla 不能双发射
- 同样可以测得通用寄存器 load 指令 ldr+fmla 的组合可以达到 float 峰值的 93%,说明 ldr 可以和 fmla 双发射
- 同上可以测得 ins + fmla 能双发射,ins + vector load 64 位 可以双发射
- 根据 Matmul 最内层 Kernel 的 计算原理,如最内层 Kernel 的分块大小是 8x12 ,那最内层需要读取:20 个 float 数据,计算 24 次 fmla 计算
- 结合上面的 MegPeak 测试的信息,我们需要找到用最少时钟完成这:20 个 float 数据 load ,和 24 次 fmla 数据计算的指令组合,因此需要将尽可能多的数据 load 和 fmla 进行双发射,隐藏数据 load 的耗时
-
最后的指令组合是:
- 使用 vector load 64 指令 + ldr + ins 组合成为一个 neon 寄存器数据,因为 ldr 和 ins 都可以和 fmla 双发射,把他们和 fmla 放在一起可以隐藏他们的耗时
- 在这 3 条指令中穿插 fmla 指令,并尽可能解决数据依赖
根据上面的指令组合可以使得 Matmul 在小核上达到计算峰值的 70%左右。
总结
MegPeak 作为一个进行高性能计算的辅助工具,能够使得开发人员轻松获得目标处理器的内在的详细信息,辅助进行对代码的性能评估,以及优化方法设计。但是 MegPeak 也有一些需要丰富的方向:
- 支持获取更多的处理器性能数据,如:L1 ,L2 cache 的大小,自动探索各种指令组合的双发射情况,并大概绘制出一个处理器后端的缩略图。如:https://en.wikichip.org/w/images/5/57/cortex-a76_block_diagram.svg
- 支持测量移动端 OpenCL 的更多细节信息,如:warp size ,local memory 大小等。
如果有同学对上面的功能感兴趣,欢迎大家提交代码。最后欢迎大家使用 MegPeak 。

{kind=link}