
这是一个创建于 1356 天前的主题,其中的信息可能已经有所发展或是发生改变。
前提:HTML 原来就包括一些<a>标签和<img>标签,现在要做的是把剩下的不在任何标签内的 URL 转为<a>标签。
尝试过写正则,反向匹配所有满足条件的,但是太复杂,遂放弃。
最后考虑先把标签内的 URL 转义,然后替换剩下的所有 URL ,最后再把转义的转回来,代码如下:
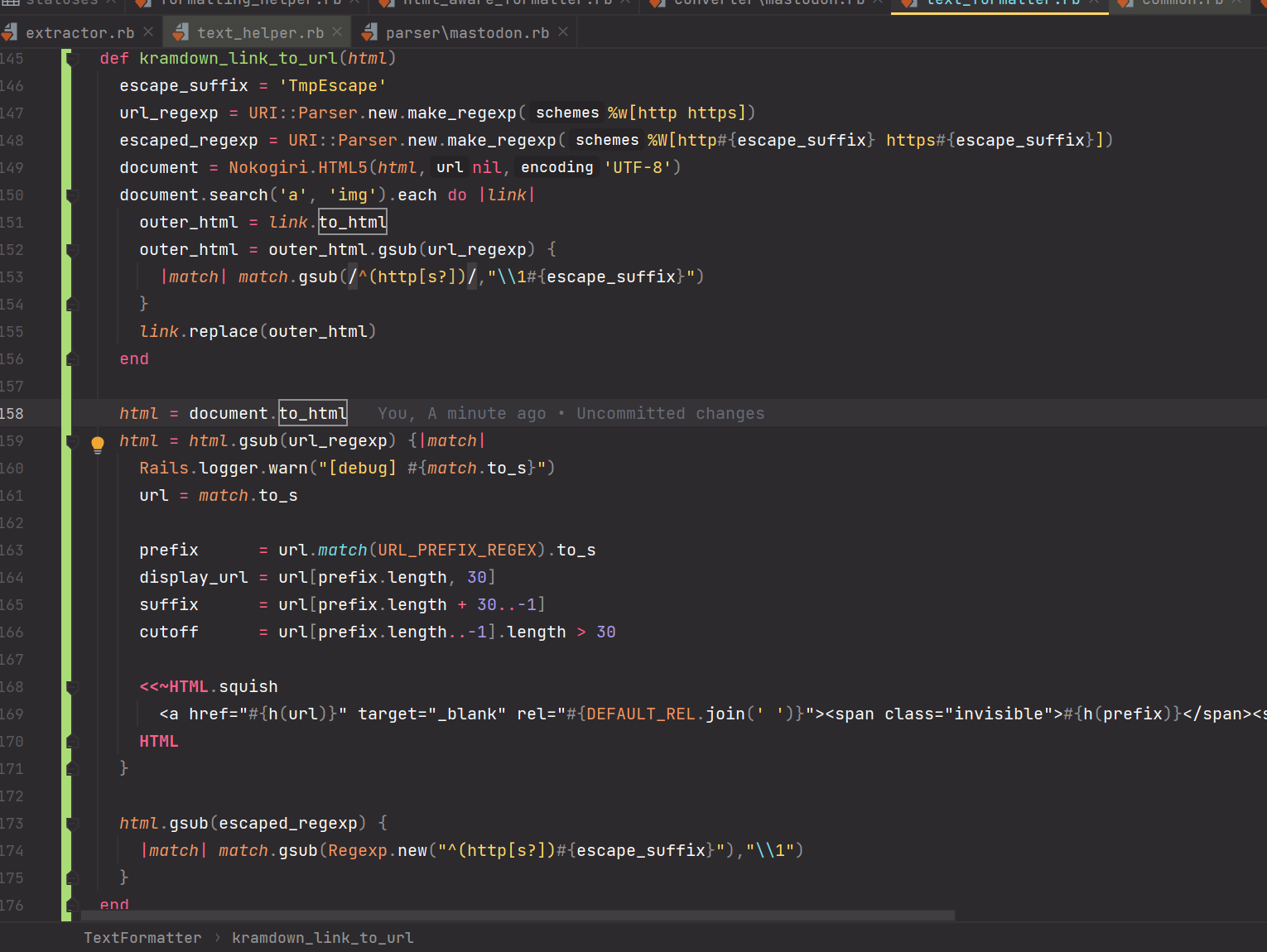
但是真的太丑了,而且存在明显的 bug ,无奈又想不出别的办法,还望大佬们给点思路
 |
1
vance123 2022 年 5 月 31 日 via Android
先解析成 Dom ,然后再用正则替换文本怎么样
|
 |
2
GeruzoniAnsasu 2022 年 5 月 31 日
ruby 不熟,库就更不了解了
你需要一个 dom visitor ,然后遍历每个节点,把节点里的 text 正则替换成<a> |
 |
3
Girlphobia 2022 年 5 月 31 日 via Android
首先解析 DOM ,然后对 DOM tree 递归遍历节点:
如果是 <a> ,跳过当前节点及所有子节点; 如果是 Text ( https://developer.mozilla.org/en-US/docs/Web/API/Text ) ,匹配 URL 正则,替换为 <a> (这里的替换实现细节可以取决于 URL 是可信的还是用户提供的,可能需要考虑 input sanitization ); 如果是其他元素,用以上逻辑递归处理所有子元素。 |
 |
4
wd 2022 年 5 月 31 日 via iPhone
你把 html 解析成 document 之后,应该就可以直接替换所有 text 里面的 url 了吧?
|
 |
5
ho121 2022 年 5 月 31 日 via Android
|
 |
6
xiangyuecn 2022 年 5 月 31 日
有多难,还解析 dom ?
1. 直接取出 body ,过滤掉 head 干扰 2. 换行符全部用占位符替换掉,比如" __换行__ " 这种不容易冲突的(首尾带空格),转成单行 3. 替换掉所有 <.*?> 包裹的内容,用占位符替换掉,内容存入 map ,比如 " __替换:123__ "(首尾带空格),map[123]="<替换掉的内容>" 4. 剩下的文本不就随便你搞了,全是纯的文本节点,简单的一个正则就能完成替换工作 5. 恢复占位符对应的内容 性能消耗完全可以忽略不计 |
|
7
GeruzoniAnsasu 2022 年 5 月 31 日
|
|
8
xiangyuecn 2022 年 5 月 31 日
@GeruzoniAnsasu 并不影响,后面会恢复回来。url 的匹配不容易误杀,url 没有空格
|