
这是一个创建于 1012 天前的主题,其中的信息可能已经有所发展或是发生改变。
目录
- [MatrixOne 数据库是什么?](#MatrixOne 数据库是什么?)
- 哈希表数据结构基础
- 哈希表基本设计与对性能的影响
-
一些常见的哈希表实现
- C++ std::unordered_map/boost::unordered_map
- go map
- swisstable
- [ClickHouse 的哈希表实现](#clickhouse 的哈希表实现)
- 高效哈希表的设计与实现
- 性能测试
- 总结
MatrixOne 数据库是什么?
MatrixOne 是一个新一代超融合异构数据库,致力于打造单一架构处理 TP 、AP 、流计算等多种负载的极简大数据引擎。MatrixOne 由 Go 语言所开发,并已于 2021 年 10 月开源,目前已经 release 到 0.3 版本。在 MatrixOne 已发布的性能报告中,与业界领先的 OLAP 数据库 Clickhouse 相比也不落下风。作为一款 Go 语言实现的数据库,居然可以与 C++实现的顶级 OLAP 数据库性能媲美,这其中就涉及到了很多方面的优化,包括高性能哈希表的实现,本文就将详细说明 MatrixOne 是如何用 Go 实现高性能哈希表的。
Github 地址: https://github.com/matrixorigin/matrixone
哈希表数据结构基础
哈希表( Hashtable )是一种非常基础的数据结构,对于数据库的分组聚合和 Join 查询的性能至关重要。以如下的分组聚合为例(备注,图引自参考文献1):
SELECT col, count(*) FROM table GROUP BY col
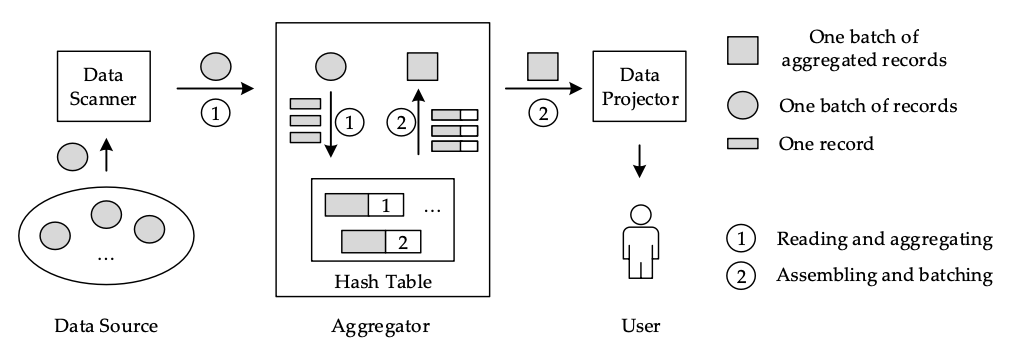
它包含两个处理阶段:第 1 阶段是使用数据源的数据建立一个哈希表。哈希表中的每条记录都与一个计数器有关。如果记录是新插入的,相关的计数器被设置为 1 ;否则,计数器被递增。第二阶段是将哈希表中的记录集合成一种可用于进一步查询处理的格式。
对于 Join 查询而言,以如下 SQL 为例:
SELECT A.left_col, B.right_col FROM A JOIN B USING (key_col)
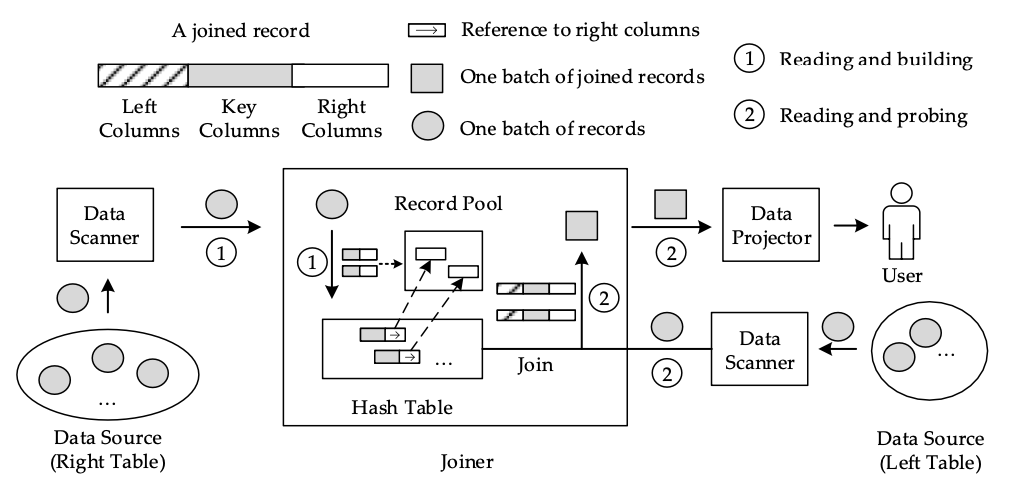
它同样也有两个阶段:第一阶段是使用 Join 语句右侧表的数据建立一个哈希表,第二阶段是从左侧表中读取数据,并快速探测刚刚建立的哈希表。构建阶段与上面的分组实现类似,但每个哈希表的槽位都存储了对右边列的引用。
由此可见,哈希表对于数据库的 SQL 基础能力起着很关键的作用 ,本文讨论哈希表的基本设计与对性能的影响,比较各种常见哈希表实现,然后介绍我们为 MatrixOne 实现的哈希表的设计选择与工程优化,最后是性能测试结果。
我们预设读者已经对文中提到哈希表相关的概念有所了解,主要讨论其对性能的影响,不做详细科普。如果对基本概念并不了解,请从其他来源获取相关知识,例如维基百科。
哈希表基本设计与对性能的影响
碰撞处理
不同的 key 经哈希函数映射到同一个桶,称作哈希碰撞。各种实现中最常见的碰撞处理机制是链地址法( chaining )和开放寻址法( open-addressing )。
链地址法
在哈希表中,每个桶存储一个链表,把相同哈希值的不同元素放在链表中。这是 C++标准容器通常采用的方式。
优点:
- 实现最简单直观
- 空间浪费较少
开放寻址法
若插入时发生碰撞,从碰撞发生的那个哈希桶开始,按照一定的次序,找出一个空闲的桶。
优点:
- 每次插入或查找操作只有一次指针跳转,对 CPU 缓存更友好
- 所有数据存放在一块连续内存中,内存碎片更少
当 max load factor 较大时,性能不如链地址法。然而当我们主动牺牲内存,选择较小的 max load factor 时(例如 0.5 ),形势就发生逆转,开放寻址法反而性能更好。因为这时哈希碰撞的概率大大减小,缓存友好的优势得以凸显。
值得注意的是,C++标准容器实现不采用开放寻址法是由 C++标准决定,而非根据性能考量(详细可见这个boost 文档)。
Max load factor
对链地址法哈希表,指平均每个桶所含元素个数上限。
对开放寻址法哈希表,指已填充的桶个数占总的桶个数的最大比值。
max load factor 越小,哈希碰撞的概率越小,同时浪费的空间也越多。
Growth factor
指当已填充的桶达到 max load factor 限定的上限,哈希表需要 rehash 时,内存扩张的倍数。growth factor 越大,哈希表 rehash 的次数越少,但是内存浪费越多。
空闲桶探测方法
在开放寻址法中,若哈希函数返回的桶已经被其他 key 占据,需要通过预设规则去临近的桶中寻找空闲桶。最常见有以下方法(假设一共|T|个桶,哈希函数为 H(k)):
- 线性探测( linear probing ):对 i = 0, 1, 2...,依次探测第 H(k, i) = H(k) + ci mod |T|个桶。
- 平方探测( quadratic probing ):对 i = 0, 1, 2...,依次探测 H(k, i) = H(k) + c<sub>1</sub>i + c<sub>2</sub>i<sup>2</sup> mod |T|。其中 c<sub>2</sub>不能为 0 ,否则退化成线性探测。
- 双重哈希( double hashing ):使用两个不同哈希函数,依次探测 H(k, i) = (H<sub>1</sub>(k) + i * H<sub>2</sub>(k)) mod |T|。
线性探测法对比其他方法,平均需要探测的桶数量最多。但是线性探测法访问内存总是顺序连续访问,最为缓存友好。因此,在冲突概率不大的时候( max load factor 较小),线性探测法是最快的方式。
其他还有一些更精巧的探测方法,例如 cuckoo hashing ,hopscotch hashing ,robin hood hashing (文章开头给的维基百科页面里都有介绍)。然而它们都是为 max load factor 较大( 0.6 以上)的情形设计的。在 max load factor = 0.5 的时候,实际测试中性能都不如最原始最直接的线性探测。
一些常见的哈希表实现
C++ std::unordered_map/boost::unordered_map
基于上面提到的原因,处理碰撞使用链地址法。默认 max load factor = 1 ,growth factor = 2 。设计简单,不用多说。
go map
通过阅读 golang 库的代码得知,golang 内置的 map 采用链地址法。
swisstable
来自于 Google 推出的abseil 库,是一款性能十分优秀的针对通用场景的哈希表实现。碰撞处理方式使用开放寻址,地址探测方法是在分块内部做平方探测。parallel-hashmap,以及 rust 语言标准库的哈希表实现,都是基于 swisstable 。更多信息可参考此处。
ClickHouse 的哈希表实现
采用开放寻址,线性探测。max load factor 为 0.5 ,growth factor 在桶数量小于 2^24 时为 4 ,否则为 2 。
针对 key 为字符串的情形,ClickHouse 还有专门的根据字符串长度自适应的哈希表实现,具体参见论文,这里不展开。
高效哈希表的设计与实现
MatrixOne 是使用 go 语言开发的数据库,市面上的知名哈希表实现我们都无缘直接使用,而在初始的实现中,我们采用了 go 语言自带的 map ,结果高基数的分组(比如多属性分组很容易做到高基数)性能相比 ClickHouse 差距会接近一个数量级,低基数也慢不少,所以我们必须实现自己的版本。
基本设计与参数选择
ClickHouse 的哈希表在自带的 benchmark 中表现出了最高的性能,因此借鉴其具体实现成为十分自然的选择。我们照搬了 ClickHouse 的如下设计:
- 开放寻址
- 线性探测
- max load factor = 0.5 ,growth factor = 4
- 整数哈希函数基于 CRC32 指令
具体原因前面已经提到,当 max load factor 不大时,开放寻址法要优于链地制法,同时线性探测法又优于其他的探测方法。
并做了如下修改(优化):
- 字符串哈希函数基于 AESENC 指令
- 插入、查找、扩张时批量计算哈希函数
-
扩张时直接遍历旧表插入新表
- ClickHouse 是先把旧表整体 memcpy 到新表中,再遍历调整位置。没找到如此设计的原因,但是经测试性能不如我们的方式。
哈希函数
哈希函数的作用是将任意的 key 映射到哈希表的一个地址,是哈希表插入和查找过程的第一步。数据库场景中使用的哈希函数,应该满足:
- 速度尽量快
- 打散得尽量均匀(避免聚集),这样使得碰撞概率尽量小,若哈希表做分区的话也可保证分得均匀
- 不需要考虑密码学安全性
在 ClickHouse 的实现中,主要使用现代 CPU ( amd64 或者 arm64 )自带的 CRC32 指令来实现哈希函数。
inline DB::UInt64 intHashCRC32(DB::UInt64 x)
{
#ifdef __SSE4_2__
return _mm_crc32_u64(-1ULL, x);
#elif defined(__aarch64__) && defined(__ARM_FEATURE_CRC32)
return __crc32cd(-1U, x);
#else
/// On other platforms we do not have CRC32. NOTE This can be confusing.
return intHash64(x);
#endif
}
经实测,打散效果非常不错,而且每个 64 位整数只需一条 CPU 指令,已经达到理论极限,速度远超 xxhash ,Murmur3 等一系列没有使用特殊指令的“普通”哈希函数。
我们的整数哈希函数也使用同样的方法实现。
TEXT ·Crc32Int64Hash(SB), NOSPLIT, $0-16
MOVQ $-1, SI
CRC32Q data+0(FP), SI
MOVQ SI, ret+8(FP)
RET
值得注意的是,go 语言不具有 C/C++/rust 的 intrinsics 函数库,因此要使用某些特殊的指令,只能用 go 汇编自己实现。而且 go 汇编函数目前无法内联,因此为了最大化性能,需要把计算哈希函数的过程做成批量化。这点将在后续的文章中具体介绍。
包含 CRC32 指令的 SSE4.2 最早见于 2008 年发布的 Nehalem 架构 CPU 。因此我们假设用户的 CPU 都支持这一指令,毕竟更老的设备用来跑 AP 数据库似乎不太合适了。
对于字符串类型的哈希函数,ClickHouse 仍然通过 CRC32 指令实现。我们经过调研,选择基于 AESENC 指令来实现。AESENC 包含在 AES-NI 指令集中,由 Intel 于 2010 年发布的 Westmere 架构中首次引入,单条指令执行 AES 加密过程中的一个 round 。AESENC 平均一条指令处理 128 位数据,比 CRC32 更快,而且提供 128 位结果,适应更多应用场景(对比 CRC32 只有 32 位)。在实测中基于 AESENC 的哈希函数打散效果同样优秀。网络上基于 AESENC 指令实现的哈希函数已经有不少,例如nabhash,meowhash,aHash。我们自己的实现在这里( amd64 )和这里( arm64 )。
特殊优化
我们针对字符串 key ,使用了一种非常规的设计:不在哈希表中保存原始的 key ,而是存两个不同的基于 AESENC 指令的哈希函数,其中一个 64 位的结果当作哈希值,另一个 128 位的结果当作“key”。192 位再加上 64 位的 value ,每个桶宽度正好是 32 字节,可完全与 CPU 的 cacheline 对齐。在碰撞处理中,不比较原始 key ,而是比较这 192 位的数据。不同的字符串两个哈希值同时碰撞的概率极低,在 AP 系统中可以忽略不计。这样做的优势是把变长字符串比较变成了定长的 3 个 64 位整数比较,而且还省掉一次指针跳转开销,大大加速碰撞检测的过程。
代码片段:
type StringHashMapCell struct {
HashState [3]uint64
Mapped uint64
}
...
func (ht *StringHashMap) findCell(state *[3]uint64) *StringHashMapCell {
mask := ht.cellCnt - 1
idx := state[0] & mask
for {
cell := &ht.cells[idx]
if cell.Mapped == 0 || cell.HashState == *state {
return cell
}
idx = (idx + 1) & mask
}
return nil
}
具体实现代码
性能测试
测试环境
- CPU:AMD Ryzen 9 5900X
- 内存:DDR4-3200 32GB
- 操作系统:Manjaro 21.2
- 内核版本:5.16.11
- 数据:ClickHouse 提供的一亿行 Yandex.Metrica 数据集
测试内容
每个测试都是顺序插入一亿条记录,再以相同顺序查找一亿条记录。过程类似如下代码所展示:
...
// Insert
for (auto k : data) {
hash_map.emplace(k, hash_map.size() + 1);
}
...
// Find
size_t sum = 0;
for (auto k : data) {
sum += hash_map[k]
}
...
整数 key 结果
下表中记录了一些哈希表实现对 Yandex.Metrica 数据集不同属性 insert/find 所用的时间,单位毫秒( ms )。
| 属性 | ParamPrice | CounterID | RegionID | FUniqID | UserID | URLHash | RefererHash | WatchID |
|---|---|---|---|---|---|---|---|---|
| 基数 | 1109 | 6506 | 9040 | 15112668 | 17630976 | 20714865 | 21598756 | 99997493 |
| ClickHouse HashMap | 67 / 46 | 175 / 147 | 154 / 141 | 1235 / 873 | 1651 / 893 | 2051 / 1027 | 1945 / 1033 | 5389 / 2040 |
| google::dense_hash_map | 767 / 758 | 273 / 262 | 261 / 260 | 1861 / 1071 | 1909 / 1020 | 2134 / 1158 | 2203 / 1156 | 6181 / 2365 |
| absl::flat_hash_map | 227 / 223 | 236 / 230 | 230 / 231 | 1544 / 1263 | 1685 / 1354 | 2092 / 1504 | 1987 / 1521 | 6278 / 3166 |
| std::unordered_map | 298 / 301 | 323 / 356 | 443 / 443 | 4740 / 2277 | 4966 / 2459 | 5473 / 3058 | 5536 / 2849 | 24832 / 6348 |
| tsl::hopscotch_map | 166 / 162 | 376 / 250 | 167 / 167 | 2151 / 920 | 2225 / 1006 | 3055 / 1278 | 2830 / 1246 | 9473 / 3170 |
| tsl::robin_map | 247 / 281 | 240 / 225 | 276 / 254 | 1641 / 1152 | 2052 / 1132 | 2445 / 1320 | 2371 / 1295 | 7409 / 2651 |
| tsl::sparse_map | 425 / 405 | 550 / 419 | 441 / 415 | 3090 / 1906 | 3773 / 2232 | 4712 / 2760 | 4508 / 2605 | 18342 / 7025 |
| go map | 361 / 433 | 537 / 482 | 461 / 460 | 3039 / 1712 | 3186 / 1818 | 4527 / 2571 | 4175 / 2411 | 15774 / 6027 |
| MatrixOne Int64HashMap | 190 / 182 | 190 / 191 | 191 / 191 | 1112 / 759 | 1160 / 793 | 1445 / 907 | 1400 / 922 | 3205 / 1613 |
可以看出当基数非常小的时候,ClickHouse 实现最快。在基数较大时,MatrixOrigin 的实现最快,且基数越大领先得越多。
字符串 key 结果
| 属性 | OriginalURL | Title | URL | Referer |
|---|---|---|---|---|
| 基数 | 8510123 | 9425718 | 18342035 | 19720815 |
| ClickHouse StringHashMap | 2840 / 1685 | 3873 / 2844 | 5726 / 3713 | 4751 / 2987 |
| ClickHouse HashMapWithSavedHash | 2628 / 1708 | 3508 / 2905 | 5332 / 3679 | 4458 / 2963 |
| ClickHouse HashMap | 3931 / 1570 | 4203 / 2573 | 7137 / 3282 | 6159 / 2644 |
| go map | 5402 / 2440 | 9515 / 4564 | 12881 / 5741 | 10750 / 4624 |
| MatrixOne StringHashMap | 1743 / 1228 | 2434 / 1829 | 2520 / 1811 | 2563 / 1955 |
结果与整数 key 类似,基数越大我们的实现领先越多。
总结
以上性能测试结果已经大大超出了我们最初的预期。我们从移植 ClickHouse 自带哈希表出发,预计由于语言差异,最终能达到 C++原版 70~80%的性能。随着反复的迭代优化,以及不断尝试改变 ClickHouse 原本的一些设计,最终在哈希表的插入和查找性能上竟然超越了 C++版本。
这说明哪怕是一些非常基础的通常被认为早已研究透了的数据结构,通过针对特定应用场景仔细的设计和部分使用汇编加速,也可让 go 实现的版本在性能上一点不输 C/C++/rust 版本。这也为我们坚持用 go 语言开发高性能数据库提供了更多信心。
参考文献
- Tianqi Zheng, Zhibin Zhang, and Xueqi Cheng. 2020. SAHA: A String Adaptive Hash Table for Analytical Databases. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
MatrixOne 社区
对 MatrixOne 有兴趣的话可以关注矩阵起源公众号或者加入 MatrixOne 社群。
 微信公众号 矩阵起源
微信公众号 矩阵起源
 MatrixOne 社区群 技术交流
MatrixOne 社区群 技术交流
8 条回复 • 2022-05-05 16:52:32 +08:00
 |
1
tairan2006 2022-04-14 17:53:47 +08:00
用泛型写个版本试试
|
 |
2
Samuelcc 2022-04-14 18:06:12 +08:00 via Android
有试过 robin hood hashmap 吗
|
 |
3
dengn OP @tairan2006 已经做了一些泛型的试验,有兴趣可以来社区一块弄啊
|
 |
5
pluvet 2022-04-14 23:37:59 +08:00
可以啊,Golang 作为带 GC 的语言能性能玩这么溜简直无敌
|
 |
6
vishun 2022-04-26 16:23:20 +08:00
想问下开放寻址法和链表法哪个占用内存小?因为开放寻址加载因子小容易扩容,但链表法又额外增加了链表的内容,是不是当加载因子达到某个临界点时,其中一个方法更节省内存?有数学的统计吗?
|
|
7
dengn OP @vishun 只有当 load factor 极低的时候,开放寻址法占的内存更多。一般情况是链表法更多。再考虑内存分配性能的话,开放寻址每次都申请整块内存,链表法内存碎片多,肯定是开放寻址法更好。所有的主打性能的 C++哈希表,都是用的开放寻址法。
|
|
8
vishun 2022-05-05 16:52:32 +08:00
那既然开放寻址法效率高,占用内存少,为什么还有那么多语言用链表法?类似 java 的 hashmap 、c#的 dictionary 还有 redis 。
|