
这是一个创建于 1772 天前的主题,其中的信息可能已经有所发展或是发生改变。
据 IDC 最新报告预测,2022 年中国 50% 以上的组织都将成为数字化坚定者,依靠新的商业模式、数字化产品与服务实现业务增长。
面对数字化转型的时代浪潮,青小云为大家准备了一份硬核大礼 —— 《数字化转型之路》,包含基础设施、业务架构、解决方案到行业实践、未来探索五个部分,该系列是对数字化转型理论与具体实践路径的系统梳理,希望帮助读者全面准确把握数字化转型发展趋势与前沿技术,促进企业与组织能够在变革的数字化世界中创造更大的价值,实现更强健的生命力。

今天与大家分享的是《数字化转型之路》中基础设施篇——超融合系统的选型与实践。
以下是分享正文:
数据中心趋势

2019 年数据中心有四大趋势,高密度服务器需要更强的计算能力,英特尔 9282 CPU 达到 58 核心,一颗 CPU 58 颗核心,两台有 100 多个核心。除了英特尔,现在很火的是国产 CPU,大家看到飞腾、华为也在发布 CPU,每个 CPU 64 核。AMD 最新的也是 64 个核心。在 2U 服务器里可以很轻松拥有 128 个核心,这是相当夸张的计算量。过去 8 部服务器也就达到 64 个核心的程度,现在核心数足够满足高密度的部署需求。
有了核心,如何解决内存?
在英特尔最新的第二代至强处理器里,现在能达到 6TB 内存,一个 2U 服务器可以达到 6TB 内存,这个内存存储量是过去小型机或者必须是 8 台服务器才可能达到的存储量。服务器性能足够强大带来的好处就是,我们可以把计算、网络、存储都放在一台服务器融合解决。
融合后解决了单个服务器的计算问题,那如何解决网络?
前面提到超融合出现的主要原因在于万兆以太网价格下降了。2019 年,25G 价格和万兆以太网是一样的价格,不要惊讶,这就是事实。
我们知道所有的产品技术,10G 芯片、25G 芯片无非是流片,流片出来后芯片用的人多,分摊的成本越低。25G 以太网从 2018 年 Q3 正式在中国大型互联网公司部署开始,只有大型互联网公司开始部署高带宽网络后,它才能给整个供应链带来巨大的需求。到现在为止 25G 网络已经是主流,给我们带来的好处是 25G 网络比原来 10G 网络还便宜。
更低延时,25G 网络基本都是配上低延迟网络使用,其中包括 RDMA、RoCE V2 和 iWarp 这三种技术,都是低延迟的网络。现在 25G 网络,能买到的 25G 的网卡都都有 RDMA 和 RoCE 功能,其成本非常低。
高速存储,PCM 存储就 Optane 和 AEP 这两种。它跟原来闪存最大的区别是延迟达到 1 个微秒和 10 个微秒级别,速度仅次于内存。 这两个产品的出现给我们服务器的配置带来新的玩法,看怎么利用 AEP 和傲腾降低写延迟,通过 AEP 方式降低内存成本。
NVMe 闪存比较常见,大概是 90 微秒左右的延迟,但是软件定义网络很重要的一点在于你全用 CPU 计算,CPU 能力耗了非常多,而且 CPU 不大适合做软件的工作,它要求高转发效率。转发效率要求 CPU 主频高,58 核心的 CPU 不可能超过 4G 主频,越高的核心数意味着主频降低。你选择超融合时希望有更高核心数时,你一定买不到主频很高的 CPU,中间是矛盾的。这时我们要怎么做?
需要我们在网卡上做工作,我们新的数据中心里所有的网络不再走 CPU,而是走网卡实现。所以要求网卡具有软件定义网络的功能,有无状态卸载能力,通过卸载加强网络包转发能力。
上一代服务器内存配置
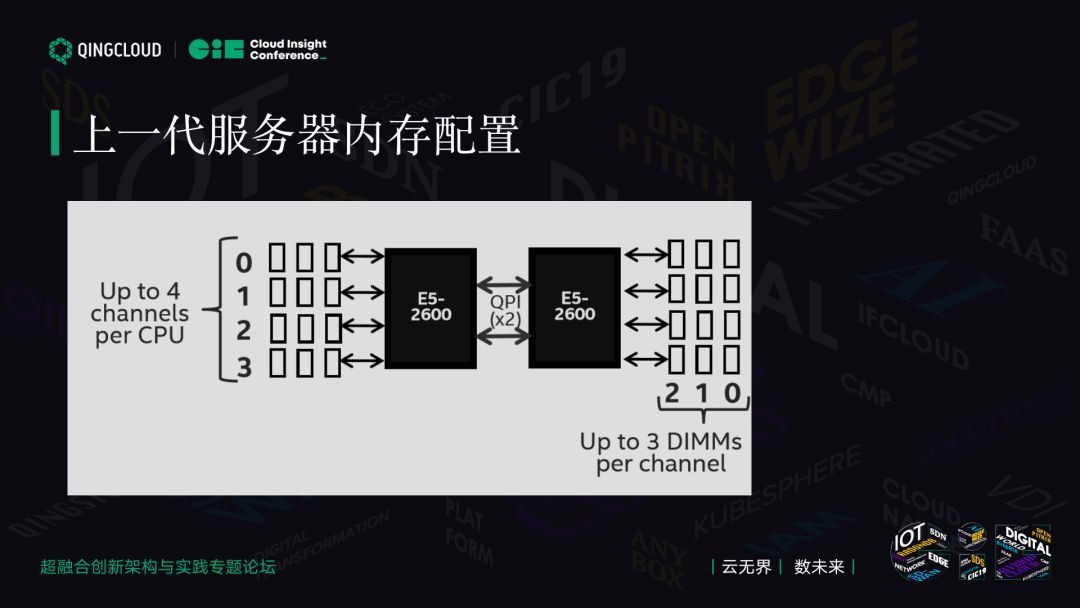
相信很多人熟悉这张图,这是英特尔上一代 CPU 的架构,对应 CPU 平台是 E5 V3 V4。
它的内存怎么放的?
每一个 CPU 放多少个,这是 12 个内存条。两路服务器一般是 24 个内存条,每个 CPU 会有三个并发 Channel,它有三个 Channel。两个 CPU 通过 QPI 互联,这边有 012 三个 Channel,每一个内存通道上有一个内存,最多在上一代 CPU 里每个内存通道里能插三个内存。大家做 PC 机的就知道,最早有 DDR 概念,单 CPU DDR 一定会配成对的内存,才能用多通道的能力。
这种架构里至少需要每个内存通道都要插一个内存,你会发现在上一代 CPU 里,如果你的内存数量是 8 的倍数,性能很好。意味着上一代 CPU 配置里应该是 128,16G 应该是 8 乘 16,128、256、512,这样的比例可以获取上一代 CPU 最强的性能。
上一代 CPU 的缺点是当你的内存离 CPU 最近时,它可能性能最高,时间低包括主频。当你把 24 个内存插满时,整个内存会降频。一般在上一代里这样的配置,24 个内存条插满,它的内存性能从 2133 会降到 1600,损失很大的内存性能。在上一代 CPU 里,一般我们最优的性能是插 8 根或者 16 根内存条。
Intel purely 平台内存配置
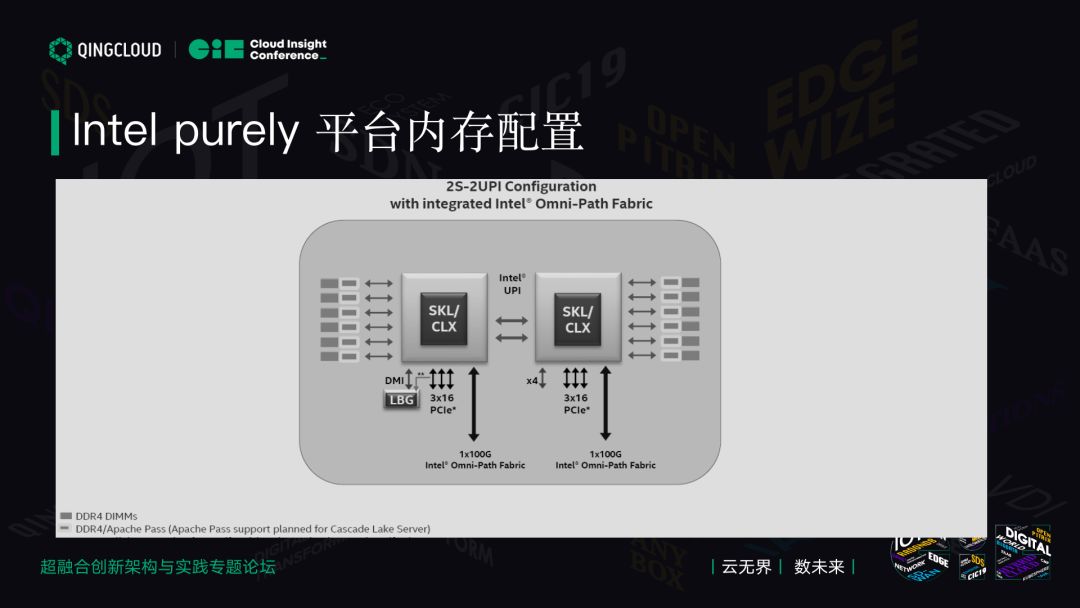
最新的 Purely 平台发生了巨大变化,每个 CPU 内存通道变成 6 个,但它还是放 12 个内存,每个通道上可以插 2 个内存,2 乘 16 还是 16 个。在这一代里,大家一推理就知道这一代一定是 12 代的倍数最好。为了性能平衡,两边数量一定是对称开放的。
我们在超融合项目里经常有客户要求配 5 根 16G 内存或者 5 根 32G 内存,非常浪费 CPU 内存通道。5 根意味着什么?意味着一边放三个,另一边放两个,完全不平衡。不平衡的话性能会达到什么样的差距?以下表为例。
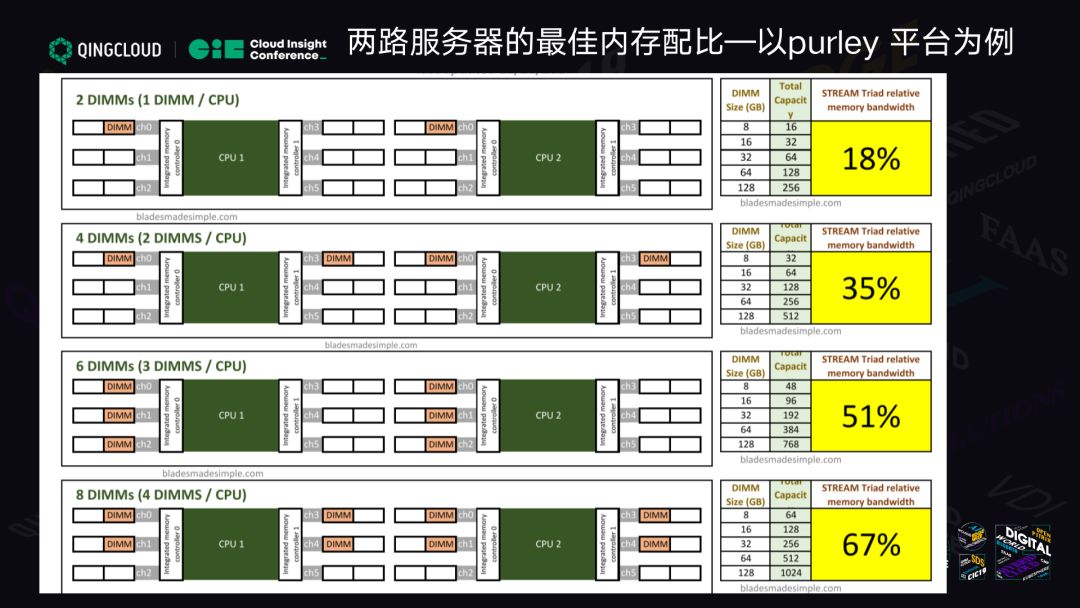
以 Purely 为例,如果每一个 CPU 配 1 根内存,你可以看到你获得的性能只有 18%。你花了大价钱买了英特尔最新的平台,你用的内存只有 18%。当你有 4 根内存条的时候,你这么放有 35% 的性能。有 6 根时有 51% 的性能,8 根的时候是上一代我最喜欢的 8 乘 16G ( 128G )的时候,你只能获得 67% 的性能。
这也是为什么很多客户那边 CPU 换了最新一代,内存还要求跟上一代一样 128,最后一测特别是用于跑 Redis 等需要内存性能的,包括内存带宽特别敏感时,发现怎么不如上一代?
那么最佳配比是怎样的?往下看。
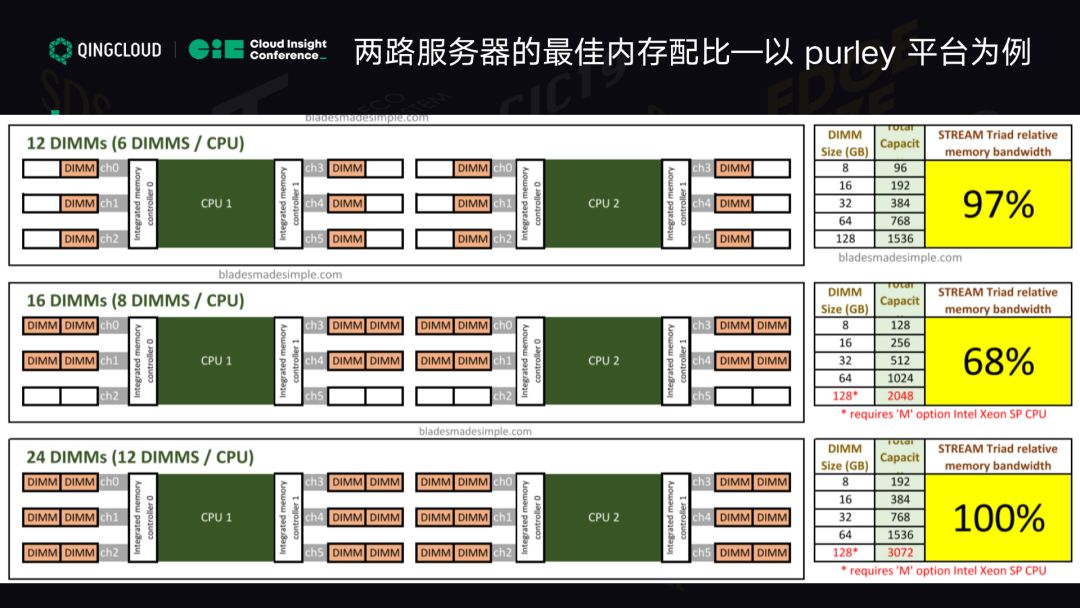
这页出现了两个最佳配比,一个方案是 2 个 CPU 各配 6 个内存,每个内存通道嵌入 0-5 都用上,这是一个完全平衡的方案,两个 CPU 完全平衡。这时候可以达到 97% 的性能。在这一代 CPU 里最高的性能是你把所有内存通道插满是百分百的性能,从成本考虑 12 根够了。
在这一代 CPU 上,最佳内存配比是 192G、384G。如果有的用户对这个了解可以推算各大云厂商的配置,你会发觉这一代无论是阿里云、腾讯云还是青云,它的虚拟机内存和最大规格刚好是这个的配比,这就是原因所在。
云计算对 I/O 的挑战
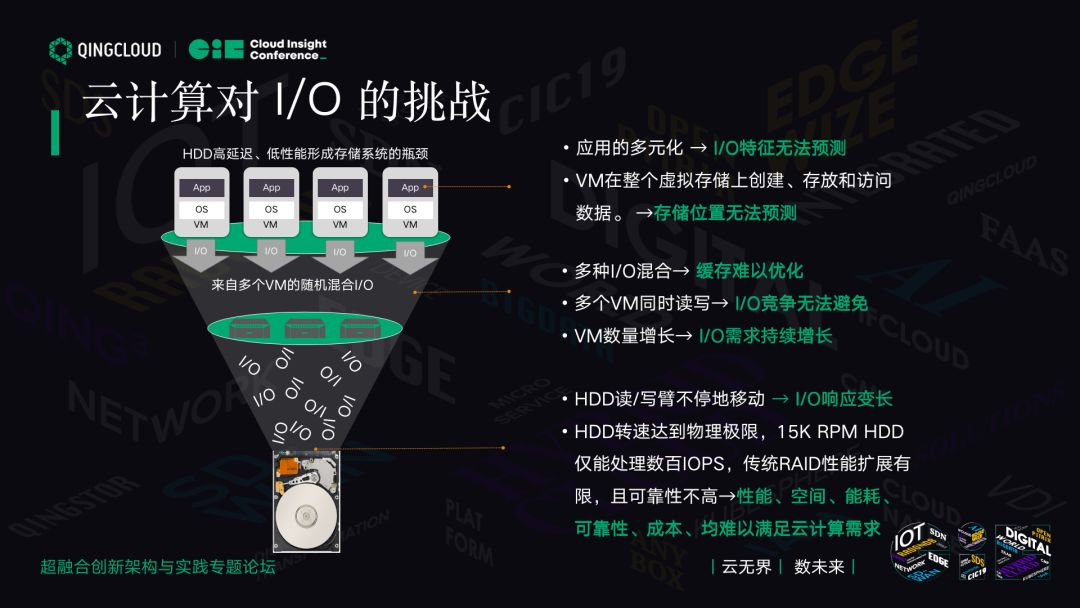
云计算无法像传统存储那样为不同的应用划分不同的卷,过去我们学存储时,它的数据存储空间一定是 8K 随机或者 4K 随机,这种随机的场景用 NFS 分卷可能更好,传统存储可以这么做。超融合不能这么做,所有的应用都是放在同样的配置和服务器上,有大块小块,也有随机的 IO。用传统 HDD 肯定无法满足,无论你怎么优化。
我们从 2014 年到 2016 年花了三年时间想尽办法把 SAS 盘的性能用到极致。2014 年上线时青云的 IO 性能在纯机械盘情况下也是最好的,我们当时是 8 万 IOPS,到现在为止青云在 IO 这一项依然是业界领先的。原因是什么?
最早我们通过机械键盘进行优化,那时候我们用了开源技术,随机顺序化获得比较好的收益。机械盘最大的问题是响应时间长,72000 转、15000 转,现在大家都不用 15000 转了,服务器也不提供 15000 转。原因在于 2016 年时 15000 转每 GB 成本高于 SSD,没必要,15000 几乎停产。现在能看到的是 7200 转和 10000 转。主流是 10000 转,在很多客户那里都是这样,但是青云不是,青云在 2016 年淘汰了所有 10000 转 SAS 硬盘。
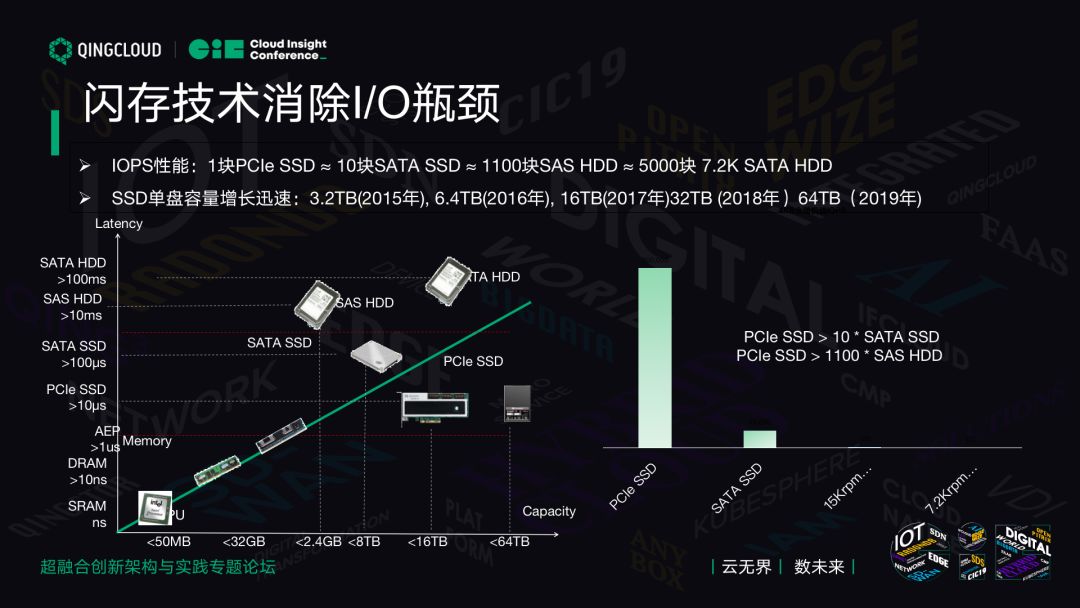
IOPS 性能方面,需要解决云计算的要求,这张表把容量跟延迟标注了出来。
SRAM,谁也买不起,这是以兆计算,一个 CPU 里多少 K 指令级缓存,那么点钱就那么点空间,非常贵。新的技术是 DRAM,内存是大家常用的。新的技术是英特尔 AEP,它介于内存和 SSD 之间。大量情况下你可以用 AEP 内存当 DRAM 使用。
现在最新的服务器上,我们最新推出的公有云实例是 E2,有一个超大内存的实例。每一个 VM 允许你挂 256G 内存,这是过去不敢想象的。这个主机利用了 AEP 的技术。AEP 和我们用 128G AEP 和 32G 内存做搭配,系统会自动把这个内存当做 AEP Cache 使用。在这种情况使用,我们经过测试,AEP 10% 的内存使用后,性能只会相对于全 DRAM 场景下降不到 10%。对大部分场景来说,如果你有大的内存需求,AEP 加上 DRAM 是非常好的帮你降低成本的方案。
从容量方面来看,我们有 1U2PB 的存储产品,这在过去是不敢想象的。为什么 1U 能做 2PB 呢?现在业界最大的单盘容量是 64TB,这个设备 1U 里有 32 个硬盘插槽,所以可以提供 2PB 的存储空间。它能提供带宽和性能是传统 SSD 无法对比的。
从图中右侧的性能来看,传统认为 1 个 SATA SSD 跟 15000 转和 72000 转比,可以看到 SATA SSD 相当于 1100 多块 SAS 机械盘,相当于 5000 块大容量 3.5 寸 SATA 机械盘的性能。1 个 PCI-E 的产品可以做到将近 10 倍的 SATA 性能,从性能来看相当于机械盘的将近 1 万倍。
这就避免了用户用机械盘造成争抢,延迟大、带来不好的体验。从 2016 年我们就下定决心做把公有云上海 1 区所有磁盘换成 PCI-E SSD。那时候很贵,但是要给用户带来体验。青云的存储,无论是公有云还是私有云性能都是非常强劲的。
NAND Flash 成本大幅下跌
谈到性能大家还会关心一点,成本,怕这个东西很好但是太贵了。之前给大家展示过 SSD 和机械盘的成本,这次不以我自己观察的数据为例,举一个公开的例子。
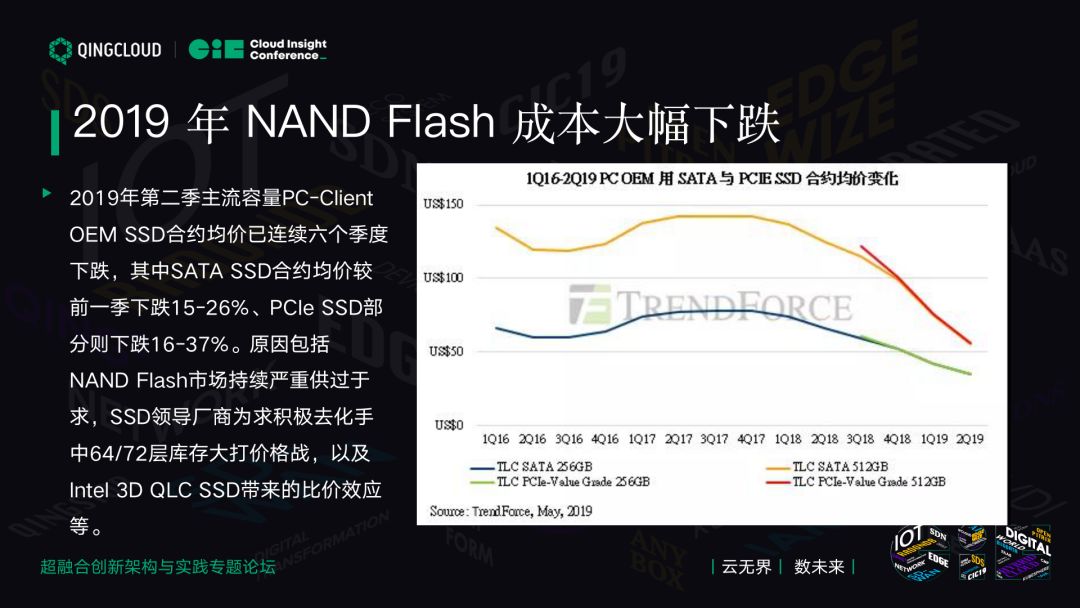
这是 TrendForce 对 NAND 价格的预测,可以看到 2017 年经历了内存的涨价,三星、美国和东芝联合涨价,发改委出面说你们这有垄断性质,2018 年开始价格飞流直下。现在可以看到下降趋势很抖,几乎到 45 度。
2018 年科技大量过剩,导致产量产能非常多。供应链上层的电子元器件价格降低了,有越来越多的 Controller,有国产的 Controller,也有国外的 Controller,价格也降低了。加上容量从原来 MLC 变 TLC,现在 QLC 出现了。同样的平米上,原来是盖别墅的,现在改一两百层的楼。这会导致原来同样面积上有更多的容量出来,价格下降了。
价格下降到什么程度?不说别的,我们看京东。找英特尔,还不是我们的国产,现在英特尔的价格是多少?历史趋势简直是跳水,2348 元 = 1.92 元 / TB。东芝 1.2 TB 价格一直波动,1 万转硬盘几年的价格差不多都这样。容量 S4510 是 1.2 元 1GB,机械盘要 1.49 元 / GB,请问还选它干嘛?

所以很多表示“需要拿 SSD 用 SAS 机械盘的 Cache”的用户,学过数学你就知道这是无厘头,你这是在拿便宜的产品当贵的产品。懂的人还好,不懂的人特别喜欢用 SATA SSD 做 Cache,SATA SSD 顺序写入性能还不如机械硬盘。
我们遇到一个真实的案例,这个案例在某一个国企里,用户非常倔,我要跑 Hadoop,你一定要用 Cache 盘,配完了写的性能从 2GB 直接降到 0.5GB 。为什么? SATA 接口 6GB 而已,SATA 机械盘 S4510 是读密集型的盘,其写的性能差不多 340 兆左右,绝对干不过 10 个机械硬盘。10 个机械硬盘组一个 Read 可以干掉 1GB 的顺序写带宽。
在这种场景下根本没有意义,这种方案纯粹浪费钱,你还要考虑缓存命中率的问题。实际可用性能更差,一旦有 Cache,最大问题是用户体验很不好。你 Cache 命中了 IOPS 很高,Cache 不命中的时候一下降到比机械盘还差。
在有 Cache 情况下,一旦没有缓存命中第一件事要做的是 Cache Miss。首先一个 IO 去查没有命中,再读机械硬盘或者写机械硬盘,性能非常差,还不如纯机械盘的场景。SAS+SATA SSD 或者 PCI-E SDD 根本没有意义。我们在超融合的推荐上,一般告诉用户直接闪存。
闪存还有一个什么好处?我们一般不告诉用户,用户很多时候不大愿意接受这一点。闪存是可以压缩的,我们提供分布式存储,闪存有 50% 以上的压缩比,实际成本变成 6 毛钱。这是为什么我们从 2016 年上海区开的时候就敢用全闪存,那时候闪存的价格大概是机械盘的 3 倍。
公有云上有一个特点,大家共用,大家的数据可能都差不多。大家知道一个 Windows Image 是多少吗?落到盘上可能不到 1G,如果你不做压缩,占用是 100GB。在公有云上,我只占用 1GB。在公有云上,我们平均的压缩率达到 40% 左右,1TB 数据写下去大概是 0.4TB 是落盘的,真正需要占用存储空间。我们才敢在 2016 年完成全闪存,我们非常开心,因为太便宜了。我们在公有云上不会再选择机械盘的方案。
网卡 Offload 对网络性能的提升

网络方面采用网卡进行硬件 Offload 的方案。在 KVM 虚拟机上用软件做 SDN,最大带宽只能达到 11.1GB 。但其实我们用的是 25G 网卡,CPU 才是瓶颈,可以看看我们公有云的 CPU 型号,已经非常高端了,但还是跑不到这个网卡的上限。
当我们开启网卡 Offload 功能后,其带宽几乎增加一倍,对 CPU 占用只增加 0.1 SI。如果是多线程的,到 45.4GB 时,我的 CPU 占用反而降低了 75%,这个 CPU 可以让我更多的使用,对公有云来说,可以降低 VM 的成本。 如果开启 Offload,单线程带宽只有八分之一的 CPU 占用,同时 PPS 提升 36%,多线程大概提高 3.8 倍左右的性能,同时 CPU 占用降低 80%。 这么简单的功能带来这么可观的收益。
由于各路友商和青云的采购,导致上游供应链成本急遽下降。这样的网卡相对于过去你用没有 Offload 的网卡,比如英特尔 8599 只剩下 100 美金,现在是人民币 700 多块钱。一台服务器怎么产也有 3 万块钱。700 块钱帮你提高这么多性能一定是值的。
我们在超融合里网卡都是 Mellanox,我们售前经销商问我们为什么一定要这家网卡?我们也想有其他家的,但比较遗憾,在业界顶尖的技术往往只有一两家可以供应。业界第一的厂商就是这家以色列公司,他们现在是最靠谱的。
RDMA 对存储性能的提升

过去 RDMA 贵,只在 HPC 高性能计算集群里用,他们需要低延时,那时候用的是专有网络,很贵。现在进入以太网,他用了一个方案是 RDMA over Converged Ethernet,这个产品在 100 英镑的网卡上,你不用再加钱,你这 100 美金既有 Offload 的功能,也会有 RDMA 的功能,花得很值。
有了 RDMA,我们只需要交换机有一个基础功能——流控,无论你是 DCB 还是其他的流控,这种情况基本普及。我们有一家合作伙伴,他们自研芯片都有这个功能。主流的华为、华三包括思科交换机都有这样的功能。在下一代芯片里,交换机流控功能都不需要就可以做到 RDMA 的低延时。
我们以存储为例,后端是闪存,我要运行程序写副本时会带来什么好处?通过 RDMA 连接以后,性能提高 38%,延迟降到 88% 左右,这是 NeonSAN 的测试。可以从这个测试上看到,延迟低于 1 毫秒的,如果没有 RDMA 网络,这个毫秒马上变得很高,从 1.2 变成 1.9,将近有 90% 的降低。
均衡扩展以提高性能
在做超融合时,计算、存储、网络一定要综合考虑,千万不要配 100 多核的 CPU,下面网络配 10G。有些用户说要用千兆网,实施人员就很痛苦,用户说我不要求性能,过几天他发现这样的机器上只能跑几个 VM,然后他就要性能上去,这很难去改。
在选择时一定要注意均衡扩展超融合的配置。
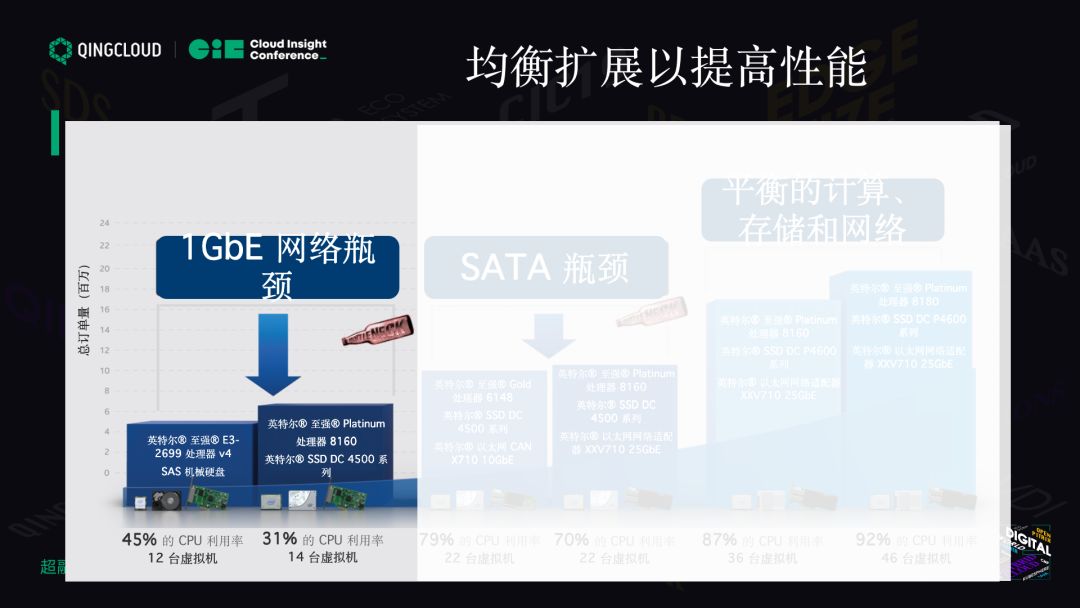
以这个为例,你用最好的 CPU 860 配机械盘能跑多少 VM ?大概 12 台 VM。换成 SSD 后,14 台 VM。瓶颈在 1GB 网络,因为它是分布式存储,它一定需要有足够带宽把它的数据副本输到另一个节点,一定是网络的瓶颈。
用户换到 10GB 网络,提高了 10 倍,VM 数量几乎提高了 1 倍。这时候发现什么问题?它选择的还是 SATA SSD,SATA SSD 是 6GB 带宽,延时很高,协议导致的。它原来是为机械盘定制的协议,不是给闪存使用的。用这么好的 CPU、网卡,25G 的只跑这一点,其实没达到省钱的目的。
真正的省钱是平衡你的计算、网络和存储。
好的 CPU、NVMe 的存储,25G 的网络,92% 的利用率,你的 CPU 没有白费,都用上了,能跑 46 台虚拟机。你这么配以后,美金数感觉好像提上去了,但其实并不亏。总体来看配低端 CPU 是价格便宜一些,但是每台上面能跑的虚拟机太少了。
从两个角度来说,硬件角度,你用高端的对用户有利,对我们没利,因为青云是卖软件的公司,用 3 台服务器解决的我只能卖 3 台服务器的软件。从折旧来看,三五年的折旧在这个方案里也是最好的。
我们从来不会坑用户,而是本着用户利益为主,用这样的机器不仅省了软件、CPU 和许可证的费用,同时你的 VM 数量提高了,这种平衡的配置给你带来总体解决方案的成本是最优的。有了性能,又有了更低的运营成本。在超融合里,大家一定注意,解决方案整体成本比单机成本更重要,一定要采用均衡的 CPU 内存和网络配置。
目前尚无回复