推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide
关于 Python 大量爬虫的问题,在同时爬大批量网站时,比如几万个,在服务器带宽有限的情况下如何优化
linhanqiu · 2018-04-07 10:29:27 +08:00 · 3822 次点击这是一个创建于 2532 天前的主题,其中的信息可能已经有所发展或是发生改变。
我这里举个例子,比如要跑一万个网站, 单机,带宽 4M,异步跑的话,必然会有很多网站传回响应会在带宽方面被限制,最次解决办法:是否增加网站的超时时间可以缓解,高级一点:可以通过引入队列,判断任务并发个数,来判断是否执行任务,来增加网站的传回响应时间以及减少网站丢失数据的可能性,更高级一点:你们来说!!!!
 |
1
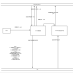
lihongjie0209 2018-04-07 11:15:32 +08:00 再跑一台 10M 带宽的机器, 只用来下载, 下载数据直接通过 redis 之类的工具传给解析器
这样做的好处: 1. 把瓶颈分离: 下载服务器只需要关注带宽, 解析服务器只需要关注 CPU 和数据库, 配置不足升级也方便 2. 好扩展: 你可以随时添加任意数量的下载服务器 |
 |
2
Nick2VIPUser 2018-04-07 11:34:27 +08:00 via iPhone
依我看最高级的就是加机器做分布式爬取,cpu 和带宽有限,这是硬性限制条件了
|
 |
3
Kilerd 2018-04-07 11:37:46 +08:00
分布式爬,做并发限制。
|
 |
4
cxh116 2018-04-07 11:39:30 +08:00 via Android
阿里云 腾讯云不限流入带宽的。
你可以在服务器上用 wget 测试一下下载文件的速度。 |
 |
5
ericbize 2018-04-07 11:45:26 +08:00 via Android
@cxh116 阿里云大概跑个 10MB/s , 腾讯云也就 2,3MB/s 感觉家里的宽带还快一点
|
 |
6
julyclyde 2018-04-07 12:07:48 +08:00
用带宽测量值反馈控制并发度
|
 |
8
silencefent 2018-04-07 14:20:39 +08:00
现在家用宽带比服务器实惠多了 200Mbps 下行 50Mbps 上行
买个 amdRyzen+16G 跑的飞起 |
 |
9
tempdban 2018-04-08 00:51:38 +08:00 via Android
硬要靠的话,我觉得可以参考 tcp 拥塞避免相关算法实现,慢启动,拥塞窗口
|