
Distributed Database Containers Deployment and Orchestration
PingCAP · 2016-11-30 15:48:10 +08:00 · 603 次点击这是一个创建于 2921 天前的主题,其中的信息可能已经有所发展或是发生改变。
本文为 11 月 12 日, PingCAP 商业产品工具方向负责人刘寅分享的《分布式数据库 TiDB 容器化部署和编排实践》内容实录,为大家详细讲解如何在 K8s 上完成一个分布式数据库系统的容器化部署和编排。
想必大家都有体会, K8s 上对于有状态的服务编排是一件比较头疼的事情。而一般的分布式系统的特点,他不仅每个节点都有存储的数据,而且他还要根据用户需要做扩容,缩容,当程序更新时要可以做到不停服务的滚动升级,当遇到数据负载不均衡情况下系统要做 rebalance ,同时为了保证高可用性,每个节点的数据会有多个副本,当单个节点遇到故障,还需要自动恢复总的副本数。而这些对于 K8s 上的编排一个分布式系统来说都是非常有挑战的。
首先介绍一下 TiDB , TiDB 是 PingCAP 开发的完全开源的分布式数据库。目前在 GitHub 上面通过搜索 TiDB 就可以找到我们的项目仓库。目前 TiDB 已经超过 5000 Star 的关注度。它实现了一个可以无限水平扩展的 OLTP 数据库,同时兼容 MySQL 的协议,你可以把他当作一个无限容量的 MySQL 来用。但又显著不同于基于 MySQL Sharding Proxy 的 中间件解决方案。我们是基于 Google 公司的 Spanner / F1 的论文基础上做的工程级开源实现,实现了真正意义的 ACID 分布式事务,还有保证多副本间的强一致数据复制。对于很多企业目前都是以 MySQL 作为业务底层的数据库存储,而 TiDB 完全兼容 MySQL 的协议,简单到复杂的 SQL 查询如 Join 、 Subquery 、 Group by 聚合查询这些 TiDB 都和 MySQL 的表现完全相同。任何可以连接 MySQL 的客户端,使用 MySQL 作为数据源的 ORM 框架,业务层都可以不改动一行代码的情况下迁移到 TiDB 上来。
下面我们介绍一下 TiDB Online DDL 的特性。在分布式系统中执行一个 DDL 操作并不像单机那么简单。因为每个节点都要保存一份数据库 Schema 信息。那么比如当需要给一个表添加一个新列,需要所有节点都重新加载自己的 Schema ,同时不能阻塞正常业务的增删改查操作,还要保证数据的正确性。
另外很重要的一点是, TiDB 可以做到自动的故障转移,甚至能做到跨数据中心的容灾。 TiDB 的每份数据都维持多个副本,使用 raft 协议保证副本间强一致性同步。实现跨数据中心甚至跨城市的数据备份。
目前 TiDB 已经成为新兴的 NewSQL 数据库领域备受关注的一个项目,同时我们的版本也在快速的迭代,不断地优化性能和提高稳定性。这个月底我们即将发布 TiDB 的 RC1 版本,而实际上已经有一些客户在线上使用它了。
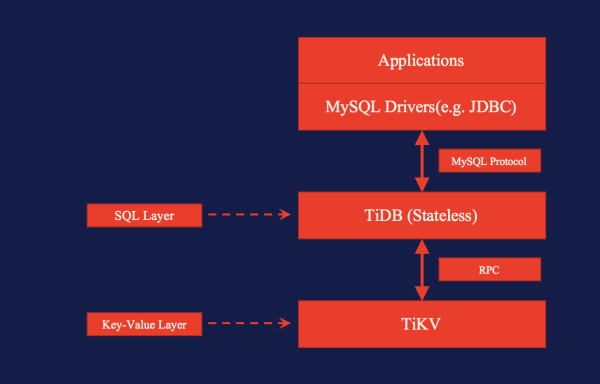
这张图简单介绍一下 TiDB 的逻辑架构,可以看出他包含两个核心的服务:上面的 tidb-server 是无状态的,他主要负责接受客户端的 query ,完成 SQL parser 和 optimizer ,转化为执行下层 TiKV 的数据请求。而 TiKV 本质上是一个支持事务的分布式 KV 引擎,他是有状态的,而且存储的每份数据都维持一个多副本。 TiKV 也可以脱离 TiDB 独立使用。
为了让大家更好的理解后面的内容,接下来展开讲一下 TiKV 的存储结构和实现原理。我们把 TiKV 存储的 key-value 按照 key 进行排序,按照 Key 的 range 划分成为很多个 Region ,每个 Region 有一个最大限制,比如 64M ,超过 64M 就要分裂成两个 Region 。这有点类似 HBase 的 Region 每个 Region 都包含多个数据副本,每个副本我们叫一个 Peer ,并通过 Raft 协议来一个 Region 中的 Peer 保持强一致性的数据同步。所以我们也把一个 Region 下的 Peer 称作一个 Raft Group 。再说说 Store ,一个 Store 是代表一个物理存储节点,可以当他是存放 Peer 的容器,这些 Region 的 Peer 在多个 Store 之间进行存储,并接受调度。
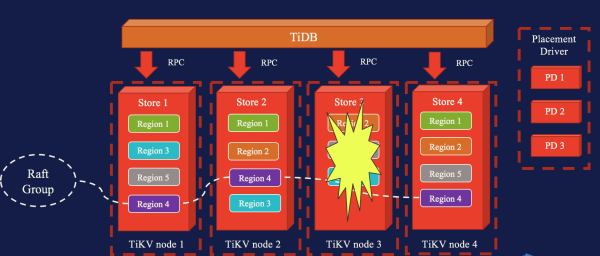
这张图中有四个 Store ,系统中一共有 5 个 Region ,每个包含 3 个 Peer ,这些 Peer 均匀分布在 4 个 Store 。可以从颜色区分 Region 。这个时候我们假设有一个节点出现了故障,宕机了。这边我们可以看到右边有一组叫做 PD 的服务,这个 PD 不是指的 GCE 上的 PD ,是我们一个服务组件,它的作用是以一个上帝的视角,对 Region 的 Peer 进行调度。刚才 Store 3 宕机会被 PD 发现,而接下来 PD 会把这些 Peer 转移到正常的 Store 上面,维持一定的副本数,并且维持负载均衡。
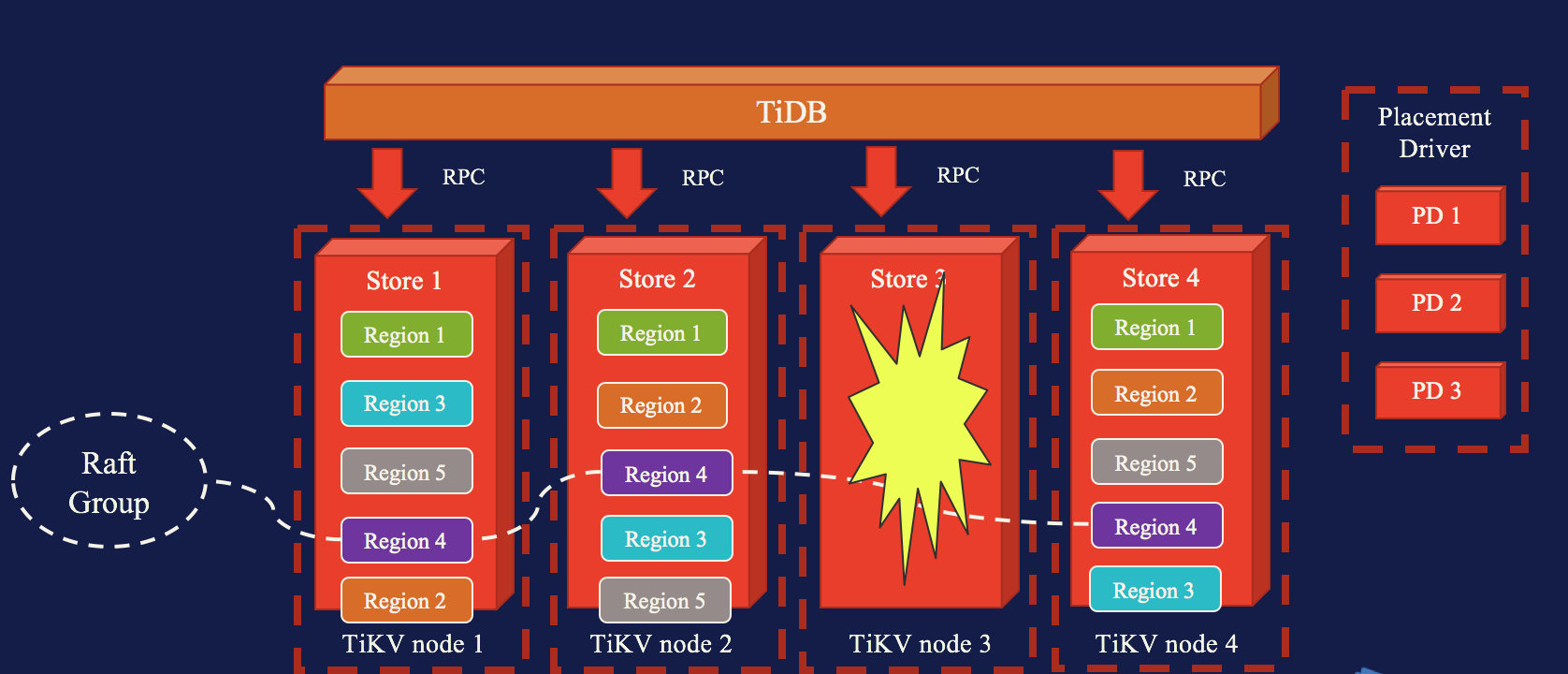
所以就这点来说, TiKV 本身设计上就非常利于容器化部署,因为 K8s 最低粒度是对 Pod 进行调度,而是没有办法对 Pod 里面的数据进行调度的。而对于 TiKV 来说, PD 实现了 Peer 级别数据层面的调度。从这个意义上来说,把 TiKV 放到 Pod 中,也可以说他是 stateless 。
然后再说一下 PD ,前面提到过 PD 的作用是在 God 的视角对整个集群数据层面来进行调度,同时也维护起整个集群的 meta 信息。 meta 信息实际是维护 Key 到具体的 Peer 的路由关系,而 TiDB 会把逻辑上对表的操作最终转换成为 KV 的存取操作,因此就需要获取 meta 信息来找到数据存放在哪个 Region 的哪个 Peer 里。
同时 PD 的一个作用就是要维持 Region 的副本数,比如配置默认副本数是 3 个,当少于 3 个时候要尝试进行恢复,当然由于 Raft 的原因如果只剩下 1 个副本就不能正常工作了。另外需要处理的是 Region 的分裂,以及把两个小的 Region 合并成一个大的 Region 。如果在一个 Store 下面 Region 的数量比较多的话, PD 会把它 rebalance 到其他相对空闲的 Store 上面。
最后 PD 建议至少启动三个实例,因为它本身也是一个 Raft 集群。

这是一个实际的部署的网络关系的拓扑。首先 TiKV 自己组成一个集群,之前维持 Raft 协议互相通讯以保证 peer 之间数据的强一致性。 PD 组成一个 Raft 集群来维护 TiKV 的 meta 信息。每个 TiKV 还要向 PD 上报心跳来更新自己的状态。
TiDB 要访问 TiKV 之前需要从 PD 获取最新的 meta 信息,当然是在 TiDB 内存里有一份缓存,所以可以看到它的网络情况还是比较复杂的,而且服务之间存在一定的依赖关系。

接下来我们看看如何把 TiDB 放进 Docker 里面启动。上图是用 Docker 启动 PD 的一个例子,高亮的这部分是一个叫 adervertise-urls 的参数。它是做什么用的呢?首先作为一个服务要有一个监听端口,但是如果服务放到 Docker 里面来跑,是需要做端口映射来映射到宿主机的端口上。所以这个 advertise-urls 就是配的宿主机的 url 和端口,告诉外面的其他服务通过这个 advertise-urls 可以访问到 Docker 里面跑着的服务。下面这个 --initial-cluster 对于熟悉 Etcd 的同学可能会比较了解。当首次创建一个无中心节点的集群,启动时需要指定初始成员都有谁,他们会组建成一个集群。当后面再有新成员加入时,必须要以 join 的方式加入。而这样的话其实对 K8s 里面部署容器编排会变的非常困难。接下来两个是 Docker 启动 TiKV 和 TiDB 的例子。相对于 PD 来说它们参数上会少一些。 TiKV 本身也有一个 advertise 这样的参数。另外 TiDB 和 TiKV 都要连 PD ,所以启动参数里面需要指定 PD 的地址。
那么接下来,我们这样一个复杂的分布式集群怎么放到 k8s 上面部署?
首先, PD 需要 scale ,但是 PD 的 scale 是困难的。因为前面说过 PD 的 scale 过程需要通过 join 的方式,有的操作可能还需要调用 PD 自己的 API 来完成。我们没有办法简单地使用 ReplicationSet 来配置 PD 。
第二点是 TiDB 服务之间依赖的较复杂。假设我们不用 k8s ,手工的去启动整套服务,需要怎么做呢?首先启动 PD ,再启动 TiKV ,最后启动 TiDB ,前一个服务没有完全启动成功,最终 TiDB 是无法工作的。那么如果把这个流程拿到 K8s 来编排,将会写出很复杂很长的 yaml 配置文件。
Services hell ,这是个什么概念呢? Service 本身是 K8s 抽象的一层概念,它非常好的把 Pod 容器和对它的访问关系做了一层抽象。比如当一个 Pod 被转移走,那么它的 IP 可能会变化,但是通过 K8s 的 DNS 机制找到这个 Service ,然后再反向代理到 Pod 内部的服务端口。借助 Service 机制是构建微服务架构的基础。但是对于我们的分布式数据库来说, Service 带来了新的问题,因为 TiKV 的 Pod 是可以无限 Scaling ,然而 Pod 因为 stateful 就必须为每个 Pod 配置一个 Service ,从而增加了配置的复杂性。另外一方面, Service 本身也是增加了一层逻辑,尽管它的代码已经写的很优化,但是由于 TiDB 内部组件之间的 RPC 非常繁重,定义过多的 Service 会略微降低系统的延迟。
目前 TiDB 还没有发布 GA ,升级镜像也是非常频繁的。滚动升级作为 K8s 的一个重要的特 性,可以做到不停业务的前提下,按顺序更新每个 Pod 的镜像。但是对于有状态的服务,如何做到不破坏 Pod 里面的数据情况下更新镜像。按照一般的思路,我们会把 Pod 的数据存储在一个 Persistent Volume 上面。目前 K8s 提供的 PV 支持只能是依赖共享存储,分布式文件系统或者 NFS 。对于 Local Storage 的支持还在激烈的讨论之中。但是对于数据库来说,他对 IO 性能非常依赖,我们很难牺牲性能把它的数据放到一个网络存储上面。
我们 TiKV 的 Pod 可能会存储很大规模的数据,甚至几十 T ,上百 T 都有可能。这导致了这个 Pod 几乎不可能接受 K8s 的 RC 调度在 Node 之间进行搬移。因此我们需要把 TiKV 的 Pod 钉在 某个 Node 上。听起来 DaemonSet 很适合这个场景。
之前我们尝试在 K8s 上部署 TiDB 做了很多尝试,部署的核心思想还是把容器的生命周期和 存储的生命周期分开对待。由于我们不知道 TiDB 的用户的 PaaS 平台的情况,如果使用的是私有云方案,会考虑使用 flocker 接 ceph ,甚至直接使用 NFS 。如果用公有云的话,情况可能好一点,比如使用 AWS EBS 或者 GCE PD 相对还是简单的,性能也可以。
K8s 在 1.3 版本推出了 Petset (现在已经改名叫 StatefulSet )。这是一个特殊的 Controller ,它的核心思想是给 Pod 赋予身份,并且建立和维护 Pod 和 存储之间的联系。当 Pod 可能被调度的时候,对应的 PV 能够跟随他绑定。但是它并没有完全解决我们的问题, PS 仍然需要依赖于 PV ,还没有提供 Local Storage 的支持,而且 PS 本身还处于 Alpha 版本阶段,未来即将发布的 1.5 会放出一些新的 feature 。
还有一个变通的解决方案是用 EmptyDir 作为 Volume 的类型。升级的时候不能使用 kubectl apply ,而是用 kubectl edit 或者 kubectl patch 这样的方式。而这个操作是几乎不可能放到编排的配置文件里维护的。
那么没有解决方案了么?就在不久之前, CoreOS 提出了一个新的扩展 K8s 的新方法和思路。 CoreOS 为 K8s 增加了一个新成员,叫作 Operator 。 Operator 其实是一种对 Controller 的扩展,它比较 cool 的地方是并没有放到 K8s 本身的项目里进行维护,它更像是一种外挂,他本身也是放到一个 Pod 里面,同时通过 master 的 api server 参与到 K8s 整体的调度和运作中。这个思路非常 hack ,你可以用写代码的方式定制 Operator ,不仅能操作 K8s 的 API ,还可以同时操作容器里的服务的 API ,不仅简化了复杂服务的编排问题,还可以自定义很多激动人心的特性出来。

为了尽量说的清晰,我后面会以 Etcd 为例,因为它相比 TiDB 来说拓扑结构更加简单些。我们要讲的 Etcd 的部署,并不是指针对作为 K8s 存储底层的 Etcd ,而是在 K8s 环境上面通过 Operator 部署一个 3 成员的 Etcd 的集群。
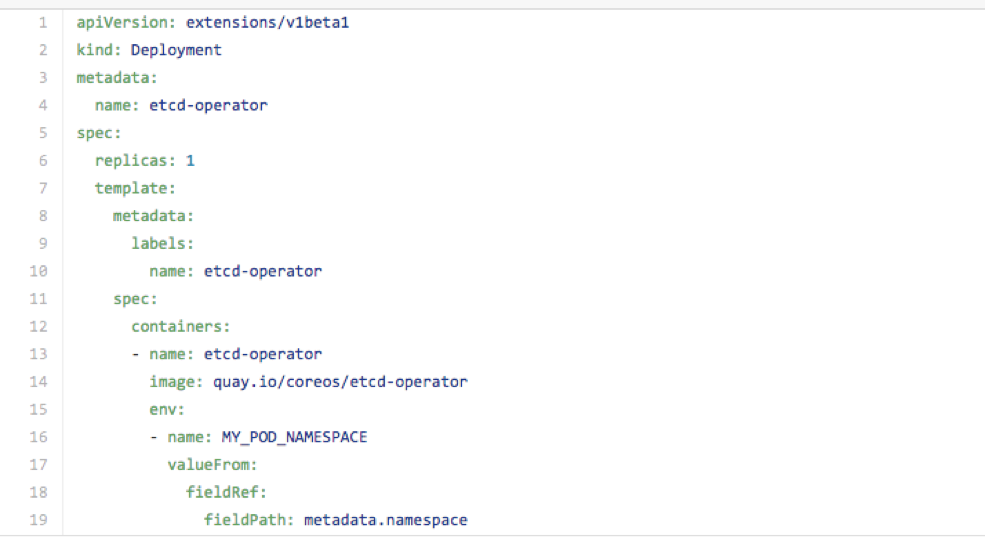 第一个步骤是部署 Operator ,这是它的编排文件。注意它的 Kind 只不过是一个简单的 Deployment ,核心是拉取一个 etcd-operator 的镜像,并配置一些环境变量。
第一个步骤是部署 Operator ,这是它的编排文件。注意它的 Kind 只不过是一个简单的 Deployment ,核心是拉取一个 etcd-operator 的镜像,并配置一些环境变量。
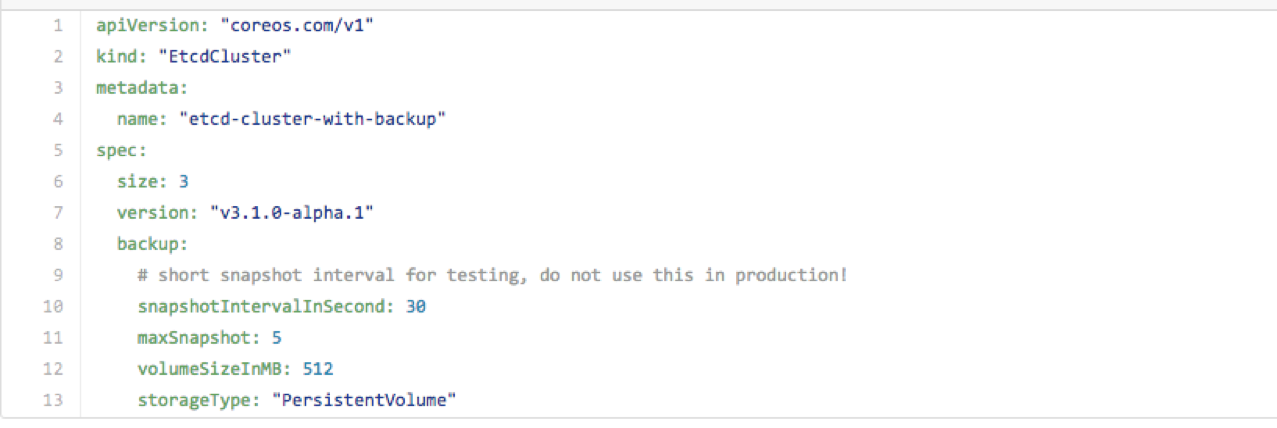
接下来就是通过 Operator 创建一个 Etcd 集群了。需要用到上面这个编排文件。注意他的类型是 etcd-cluster 。这也是前面一个 Deployment 创建的 etcd-operartor Pod 启动时利用 K8s 的 Third Party Resource 机制注册了一个新的资源,叫做 etcd-cluster 。它的 spec 部分我们可以发现他完全是针对 Etcd 集群定制了一套配置。比如集群规模 size ,镜像版本,还有一些备份策略相关的参数。在这里他设定了每隔 30 分钟进行一次备份,保留 5 个 snapshot 。
启动之后我们把 pod 列出来,会发现不仅包括三个 Etcd 的 Pod ,另外还有额外的一个 Backup 的 Pod ,它也就是前面配置的用来备份 Etcd 集群数据的专属容器。而这一切都是 Operator 替我们完成,我们还可以用一个 Operator 同时管理多个 Etcd 集群,每创建一个 etcd-cluster 类型的资源,就创建了一个 Etcd 集群。 Operator 还会参与整个 K8s 的调度,比如他发现某个 Etcd 集群的某个节点挂掉了,他会进入恢复流程利用 Raft 甚至上一个备份数据进行恢复。或者是发现用户修改了某个集群的 size ,需要由 3 个 scale 到 5 个。或者是检测到用户希望提升某个集群的镜像版本,他会执行滚动升级,等等。此外还有更多激动人心的 feature 正在开发中。
下面简单介绍一下 Operator 的实现原理,首先 Operator 把自己放到一个 Pod 里面,而他本身是一个 Go 写的小服务,直接通过调用 kubecli 的包把自己注册到 master ,成为一个 特殊的 controller 。同时他还要创建一个叫 etcd-cluster 的 TPR ,其实是自定义了一个数据结构。用户可以通过定制 yaml 编排文件,把期望的配置项生成一个 TPR 实例存储在 K8s 里面。大家可能了解 K8s 一个基本机制就是 Reconciliation , etcd-operator 作为一个 Controller 在任期之内会对 Etcd 集群状态进行 Reconciling 。比如说用户把一个集群的配置 Size 由 3 改到 5 , 然后执行 patch 命令通知 K8s 生效。 Operator 会发现用户提交的配置和系统当前的配置不一致,然后他就会按照 Etcd 自己的方式进行 scale 。具体来说,第一个 member 是当作 initial member ,后面增加成员,就需要 join 的方式调用 Etcd API 来添加新成员,最终把 3 个节点加到 5 个节点。
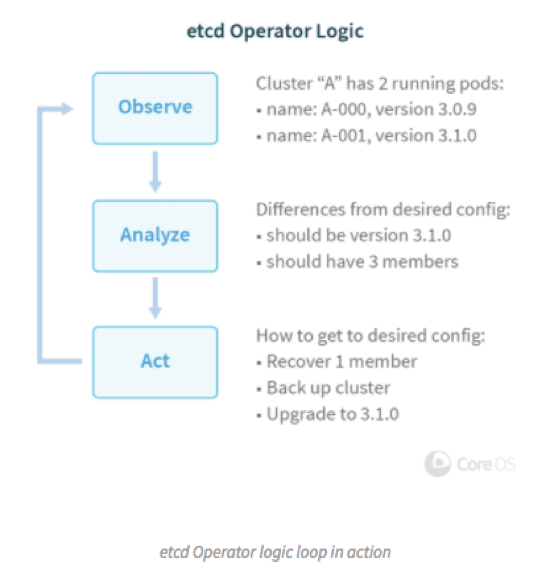
这是一个 Etcd Operator 官方的一个示例,跟我前面讲的差不多。 Operator 工作过程分为发现,分析,执行这三个阶段,发现就是找出用户希望的配置和当前实际在运行的配置的区别,分析过程就是制定一个最小代价的操作路径,放到执行阶段来做。
接下来是一个 Backup 的例子:

他是 Operator 定制化功能的一个体现。 Operator 为每个集群创建了一个专门用于备份的 Pod ,这个 Pod 挂载了一个比较大容量的 PV 。根据用户配置的备份周期,它定期从 Etcd 集群拉取 snapshot ,保存到最近的 N 份到 PV 盘上。这里可能会有疑问, Etcd 本身是 Raft 来保证高可用,那么为什么还需要一个 Pod 专门用来做备份。这是因为 Raft 只有保证多数派存活的情况下能够恢复整个集群,如果极端情况下所有副本的数据都损坏了,就只能从最近的一个备份进行恢复。但实际情况都损坏的情况并不多见,所以 Operator 在恢复整个集群的时候也做的比较智能,他会选择一个存活的节点先试着把 snapshot 获取出来,然后销毁掉所有节点,用前面的 snapshot 创建一个 initial 成员,再把其他成员 join 进来,恢复一个完整的集群。
同时在滚动升级之前也需要常规地先做一次 snapshot 备份,这样当升级的过程中可能会遇到问题导致需要回滚,由于数据兼容性等造成数据损坏,那么也可以通过之前的备份进行恢复。
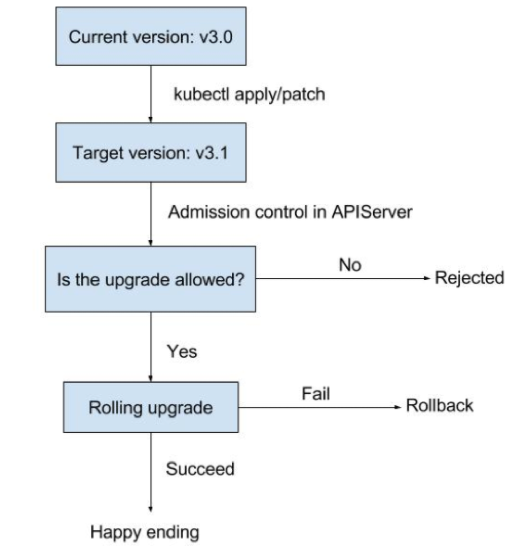
这是一个滚动升级的过程演示。首先用户 apply 通知 K8s 把 Etcd 集群的镜像升级到一个新版本, Operator 发现差异它就会触发一个滚动升级的过程。这里面还可以扩展很多东西,比如增加对升级路径的约束, 3.0 版本不可以降级到 2.0 ,只能升级到 3.1, 3.2 这样的版本。假如说 4.0 版本 Etcd 的存储结构发生变化,那么也是不允许直接升级的,避免造成数据损坏。
Operator 为 TiDB 的编排提供了一个很好的思路,我们还可以加入更多的可能性,比如说 auto-scale 的特性,可以通过 TiDB 的 API 获取负载情况,据此来进行自动 scale-out / scale-in ,更加智能地使用集群资源。另外我们还可以添加自己的监控,对于集群故障,自动恢复,容量警告等,配置规则进行报警。
对于复杂的分布式系统的在 K8s 上进行编排,我们相信会有更多的 Operator 出现。其实, CoreOS 推出 etcd-operator 同时还发布了 prometheus-operator , Prometheus 是很好的一个监控系统。
目前 TiDB 的 Operator 我们正在开发之中。 TiDB 部署的复杂程度比 Etcd 更高,它还存在多级服务之间的依赖问题。并且对于数据库而言,他存储的数据更加庞大,滚动升级,以及备份和恢复的方案也是相当有挑战。不过相信我们一定会实现一键把 TiDB 这样复杂的分布式系统在 K8s 上轻松跑起来,并且实现更加激动人心的功能。
Q&A
提问: TiDB 我也部署过,我们现在也在考虑如何把数据库进行容器化部署。目前用 K8s 还不支持 local storage 。 那么 Operator 如何解决存储的问题的呢?
刘寅:这是一个好问题,感谢。首先 Operator 本身并不能帮你解决存储的问题,他只是让你可以按照自己的方式来解决存储的问题。目前 TiDB 的方案是使用 EmptyDir 作为存储盘,在升级镜像的时候, Operator 通过 Patch 的方式通知 K8s 进行镜像升级,这样是可以不破坏 EmptyDir 的数据的。当然这也仅仅是一个临时方案。我们也很期待 K8s 1.5 的新特性对 LocalStorage 的支持。
提问:我看官方说 Petset 后续可能会考虑 local storage 的支持。另外,业界现在数据库产品做容器化方案基本上编排都是自己写的,再调度到本机的 SSD ,因为 TiDB 本身后端存储是 TiKV ,它对 IO 依赖肯定是比较重的,包括我们部署的时候贵司工程师也提到这块,其实我也想知道我一直关注这个,听说你们在做这块尝试,所以我今天特地来看一下有没有实质性的进展,特别是在 local storage 怎么做,因为你毕竟还是要部署在 k8s 上,那么存储这块一定是要解决这个问题。
刘寅:看来大家都在存储的方面遇到阻碍。在 1.5 之前,我们的方案是这样的,比如用 emptyDir 的方案,或者 HostPath 也行。而官方对于 Local Storage 的方案如何实现,讨论也是很激烈的。其实更多的是一些原则性问题,本身 K8s 设计之初重点是放在 stateless 的服务部署,对于 Local Storage 的需要把 Pod 固定在具体的 Node 之上,这需要做一些 tradeoff 。不过我们还是相信后面的 K8s 会越来越重视 stateful 的服务编排问题, PetSet 改名为 Stateful 也说明了这一点,我们拭目以待吧。
目前尚无回复