
这是一个创建于 3113 天前的主题,其中的信息可能已经有所发展或是发生改变。
经过多年信息化建设,我们已经进入一个神奇的“大数据”时代,无论是在通讯社交过程中使用的微信、 QQ 、电话、短信,还是吃喝玩乐时的用到的团购、电商、移动支付,都不断产生海量信息数据,数据和我们的工作生活密不可分、须臾难离。
什么是大数据
什么是大数据,多大算大, 100G 算大么?如果是用来存储 1080P 的高清电影,也就是几部影片的容量。但是如果 100G 都是文本数据,比如云智慧透视宝后端 kafka 里的数据,抽取一条 mobileTopic 的数据如下: [ 107 , 5505323054626937 ,局域网,局域网, unknown , 0 , 0 , 09f26f4fd5c9d757b9a3095607f8e1a27fe421c9 , 1468900733003 ] ,这种数据 100G 能有多少条,我们可想而知。
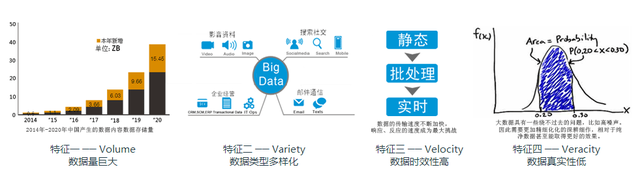
数据之所以为大,不但是因为数据量的巨大,同时各种渠道产生的数据既有 IT 系统生成的标准数据,还有大量多媒体类的非标准数据,数据类型多种多样,而且大量无用数据充斥其间,给数据的真实性带来很大影响,此外很多数据必须实时处理才最有价值。
一般数据量大(多)或者业务复杂的时候,常规技术无法及时、高效处理如此大量的数据,这时候可以使用 Hadoop ,它是由 Apache 基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,编写和运行分布式应用充分利用集群处理大规模数据。 Hadoop 可以构建在廉价的机器上,比如我们淘汰的 PC Server 或者租用的云主机都可以拿来用。
今天,云智慧的李林同学就为大家介绍一下 Hadoop 生态圈一些常用的组件。
Gartner 的一项研究表明, 2015 年, 65%的分析应用程序和先进分析工具都将基于 Hadoop 平台,作为主流大数据处理技术, Hadoop 具有以下特性:
方便: Hadoop 运行在由一般商用机器构成的大型集群上,或者云计算服务上
健壮: Hadoop 致力于在一般商用硬件上运行,其架构假设硬件会频繁失效, Hadoop 可以从容地处理大多数此类故障。
可扩展: Hadoop 通过增加集群节点,可以线性地扩展以处理更大的数据集。
目前应用 Hadoop 最多的领域有:
1) 搜索引擎, Doug Cutting 设计 Hadoop 的初衷,就是为了针对大规模的网页快速建立索引。
2) 大数据存储,利用 Hadoop 的分布式存储能力,例如数据备份、数据仓库等。
3) 大数据处理,利用 Hadoop 的分布式处理能力,例如数据挖掘、数据分析等。
Hadoop 生态系统与基础组件
Hadoop2.0 的时候引入了 HA(高可用)与 YARN(资源调度),这是与 1.0 的最大差别。 Hadoop 主要由 3 部分组成: Mapreduce 编程模型, HDFS 分布式文件存储,与 YARN 。
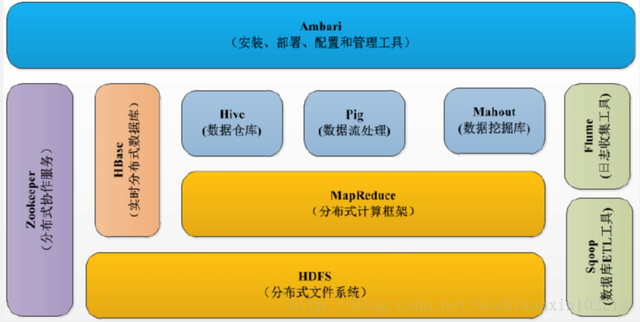
上图是 Hadoop 的生态系统,最下面一层是作为数据存储的 HDFS ,其他组件都是在 HDFS 的基础上组合或者使用的。 HDFS 具有高容错性、适合批处理、适合大数据处理、可构建在廉价机器上等优点,缺点是低延迟数据访问、小文件存取、并发写入、文件随机修改。
Hadoop MapReduce 是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上 TB 级别的海量数据集。这个定义里面有几个关键词:软件框架、并行处理、可靠且容错、大规模集群、海量数据集就是 MapReduce 的特色。

MapReduce 经典代码(wordCount)
上面这段代码就是接收一堆文本数据,统计这些文本数据中每个单词出现的次数。 MapReduce 也是一个计算模型,当数据量很大时,比如 10 个 G ,它可以把这 10G 的数据分成 10 块,分发到 10 个节点去执行,然后再汇总,这就是并行计算,计算速度比你一台机器计算要快的多。
HBase
Hadoop 的主要组件介绍完毕,现在看下 HBase ,它是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用 Hbase 技术可在廉价 PC Server 上搭建大规模结构化存储集群。 HBase 是 Google Bigtable 的开源实现,与 Google Bigtable 利用 GFS 作为其文件存储系统类似, HBase 利用 Hadoop HDFS 作为其文件存储系统; Google 运行 MapReduce 来处理 Bigtable 中的海量数据, HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据; Google Bigtable 利用 Chubby 作为协同服务, HBase 利用 Zookeeper 作为对应。
有人问 HBase 和 HDFS 是啥关系, HBase 是利用 HDFS 的存储的,就像 MySQL 和磁盘, MySQL 是应用,磁盘是具体存储介质。 HDFS 因为自身的特性,不适合随机查找,对更新操作不太友好,比如百度网盘就是拿 HDFS 构建的,它支持上传和删除,但不会让用户直接在网盘上修改某个文件的内容。
HBase 的表有以下特点:
1 ) 大:一个表可以有上亿行,上百万列。
2 ) 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3 ) 稀疏:对于为空( NULL )的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase 提供的访问方式有命令行 shell 方式, java API(最高效和常用的), Thrift Gateway 支持 C++, PHP , Python 等多种语言。
HBase 的使用场景:
需对数据进行随机读操作或者随机写操作;
大数据上高并发操作,比如每秒对 PB 级数据进行上千次操作;
读写访问均是非常简单的操作,比如历史记录,历史订单查询,三大运营商的流量通话清单的查询。

HBase 在淘宝的应用场景
Hive
之前我们说了 MapReduce 计算模型,但是只有懂 Java 的才能撸代码干这个事,不懂 Java 的想用 Hadoop 的计算模型是不是就没法搞了呢?比如 HDFS 里的海量数据,数据分析师想弄点数据出来,咋办?所以就要用到 Hive ,它提供了 SQL 式的访问方式供人使用。
Hive 是由 Facebook 开源, 最初用于解决海量结构化的日志数据统计问题的 ETL(Extraction-Transformation-Loading) 工具, Hive 是构建在 Hadoop 上的数据仓库平台,设计目标是可以用传统 SQL 操作 Hadoop 上的数据,让熟悉 SQL 编程的人员也能拥抱 Hadoop (注意。是数据仓库。不是数据库啊。)
使用 HQL 作为查询接口
使用 HDFS 作为底层存储
使用 MapReduce 作为执行层
所以说 Hive 就是基于 Hadoop 的一个数据仓库工具,是为简化 MapReduce 编程而生的,非常适合数据仓库的统计分析,通过解析 SQL 转化成 MapReduce ,组成一个 DAG(有向无环图)来执行。
Flume
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、 聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时, Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前 Flume 有两个版本 Flume 0.9X 版本的统称 Flume-og , Flume1.X 版本的统称 Flume-ng ,由于 Flume-ng 经过重大重构,与 Flume-og 有很大不同,使用时请注意区分。
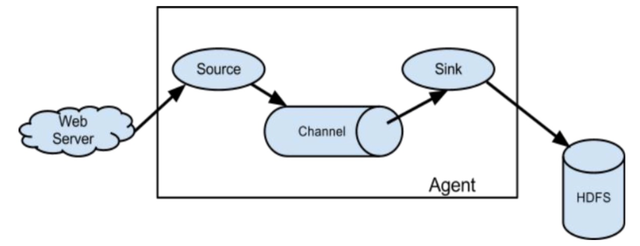
Flume 就是一个数据管道,支持很多源(source), sink(目标),和透视宝的 suro 很像,比如拉取 nginx 日志可以拿这个工具简单一配就可用。当然每台 nginx 服务器上都要配置并启动一个 flume.
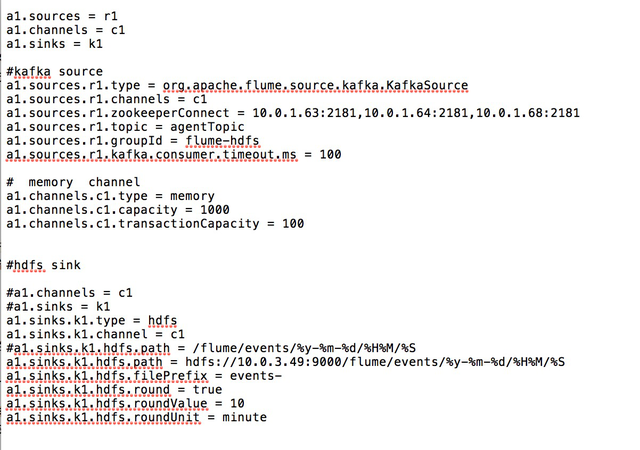
下面给大家看看配置文件(把 kafka 的数据写入 hdfs 的配置),配置很简单.完全免去了自己写一个 kafka 的 consumer 再调用 hdfs 的 API 写数据的工作量.
YARN
YARN 是 Hadoop 2.0 中的资源管理系统,它的基本设计思想是将 MRv1 中的 JobTracker 拆分成了两个独立的服务:一个全局的资源调度器 ResourceManager 和每个应用程序特有的应用程序管理器 ApplicationMaster ,该调度器是一个 "纯调度器",不再参与任何与具体应用程序逻辑相关的工作,而仅根据各个应用程序的资源需求进行分配,资源分配的单位用一个资源抽象概念 "Container" 来表示, Container 封装了内存和 CPU 。此外,调度器是一个可插拔的组件,用户可根据自己的需求设计新的调度器, YARN 自身提供了 Fair Scheduler 和 Capacity Scheduler 。
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序的提交、与调度器协商资源以启动 ApplicationMaster 、监控 ApplicationMaster 运行状态并在失败时重新启动等。
Ambari
Ambari 是一个集群的安装和管理工具,云智慧之前用的是 Apache 的 Hadoop ,运维同学用源码包安装,一个个配置文件去改,再分发到各个节点,中间哪一步搞错了,整个集群就启动不起来。所以有几个厂商提供 Hadoop 的这种安装和管理平台,主要是 CDH 和 HDP ,国内的很多人都用 CDH 的,它是 Cloudera 公司的,如果用它的管理界面安装,集群节点超过一定数量就要收费了。
Ambari 是 Apache 的顶级开源项目,可以免费使用,现在用的人也很多。 Ambari 使用 Ganglia 收集度量指标,用 Nagios 支持系统报警,当需要引起管理员的关注时(比如,节点停机或磁盘剩余空间不足等问题),系统将向其发送邮件。
ZooKeeper
随着计算节点的增多,集群成员需要彼此同步并了解去哪里访问服务和如何配置, ZooKeeper 正是为此而生的。 ZooKeeper 顾名思义就是动物园管理员,它是用来管大象(Hadoop) 、蜜蜂(Hive) 和 小猪(Pig) 的管理员, Apache Hbase 和 Apache Solr 以及 LinkedIn sensei 等项目中都采用到了 Zookeeper 。 ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,以 Fast Paxos 算法为基础实现同步服务,配置维护和命名服务等分布式应用。
其他组件
以上介绍的都是 Hadoop 用来计算和查询的比较常用和主流的组件,上面那副生态图中的其他几个组件简单了解一下就好:
Pig 是一种编程语言,它简化了 Hadoop 常见的工作任务, Pig 为大型数据集处理提供了更高层次的抽象,与 MapReduce 相比, Pig 提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。
Mahout 是 Hadoop 提供做机器学习用的,支持的算法也比较少,但是一些常用的 k-means 聚类、分类还是有的,他是用 MapReduce 做的,但是 MapReduce 不太擅长这个东西,所以 Mahout 的作者也转投 spark ML 阵营了。
Sqoop 是数据库 ETL 工具,用于将关系型数据库的数据导入到 Hadoop 及其相关的系统中,如 Hive 和 HBase 。 Sqoop 的核心设计思想是利用 MapReduce 加快数据传输速度,也就是说 Sqoop 的导入和导出功能是通过 MapReduce 作业实现的,所以它是一种批处理方式进行数据传输,难以实现实时数据的导入和导出。比如云智慧监控宝以前的业务数据都存在 MySQL ,随着数据量越来越大,要把数据导到 Hbase ,就可以拿 Sqoop 直接操作。
本文所介绍的东西都是用于离线计算的,而之前发布的《面临大数据挑战 透视宝如何使用 Druid 实现数据聚合》则是关于实时计算的框架 Druid 的。大数据常用的流计算框架主要有 Storm , Spark Streaming , Flink , Flink 虽然是 2014 年加入 Hadoop 的,但至今在生产环境上用的人还不多,似乎大家都持观望态度。
说一下流计算(Druid , Spark Streaming)和批处理(MapReduce , Hive)有啥区别,比如电商网站的个性化广告投放,当我们访问了亚马逊搜索笔记本电脑之后,他就会给你推荐很多笔记本电脑链接,你的请求和兴趣爱好被亚马逊服务器实时接收,流计算分析之后当时就会推荐给你可能会购买的东西。如果这个东西拿批处理去做,服务端收集完了,过半个小时才算出你可能要买电脑,这时候再给你推荐电脑明显就不合适了,因为这时候你可能在搜索电炒锅……
最后再说一下大数据的工作流,比如有两个 MapReduce 的任务是有依赖的,必须第一个完成了才能执行第二个,这就需要一个调度工具来调度。 MapReduce 也提供调度的 API ,但是代码要写很多,上面的代码截图只是一部分,这个依赖我写了大概 150 行。所以这时候出现了工作流,用工作流来管理我们的各个 job ,我目前知道的有 oozie 和 azkaban , oozie 的配置比较灵活,推荐大家使用。

什么是大数据
什么是大数据,多大算大, 100G 算大么?如果是用来存储 1080P 的高清电影,也就是几部影片的容量。但是如果 100G 都是文本数据,比如云智慧透视宝后端 kafka 里的数据,抽取一条 mobileTopic 的数据如下: [ 107 , 5505323054626937 ,局域网,局域网, unknown , 0 , 0 , 09f26f4fd5c9d757b9a3095607f8e1a27fe421c9 , 1468900733003 ] ,这种数据 100G 能有多少条,我们可想而知。

数据之所以为大,不但是因为数据量的巨大,同时各种渠道产生的数据既有 IT 系统生成的标准数据,还有大量多媒体类的非标准数据,数据类型多种多样,而且大量无用数据充斥其间,给数据的真实性带来很大影响,此外很多数据必须实时处理才最有价值。
一般数据量大(多)或者业务复杂的时候,常规技术无法及时、高效处理如此大量的数据,这时候可以使用 Hadoop ,它是由 Apache 基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,编写和运行分布式应用充分利用集群处理大规模数据。 Hadoop 可以构建在廉价的机器上,比如我们淘汰的 PC Server 或者租用的云主机都可以拿来用。
今天,云智慧的李林同学就为大家介绍一下 Hadoop 生态圈一些常用的组件。
Gartner 的一项研究表明, 2015 年, 65%的分析应用程序和先进分析工具都将基于 Hadoop 平台,作为主流大数据处理技术, Hadoop 具有以下特性:
方便: Hadoop 运行在由一般商用机器构成的大型集群上,或者云计算服务上
健壮: Hadoop 致力于在一般商用硬件上运行,其架构假设硬件会频繁失效, Hadoop 可以从容地处理大多数此类故障。
可扩展: Hadoop 通过增加集群节点,可以线性地扩展以处理更大的数据集。
目前应用 Hadoop 最多的领域有:
1) 搜索引擎, Doug Cutting 设计 Hadoop 的初衷,就是为了针对大规模的网页快速建立索引。
2) 大数据存储,利用 Hadoop 的分布式存储能力,例如数据备份、数据仓库等。
3) 大数据处理,利用 Hadoop 的分布式处理能力,例如数据挖掘、数据分析等。
Hadoop 生态系统与基础组件
Hadoop2.0 的时候引入了 HA(高可用)与 YARN(资源调度),这是与 1.0 的最大差别。 Hadoop 主要由 3 部分组成: Mapreduce 编程模型, HDFS 分布式文件存储,与 YARN 。

上图是 Hadoop 的生态系统,最下面一层是作为数据存储的 HDFS ,其他组件都是在 HDFS 的基础上组合或者使用的。 HDFS 具有高容错性、适合批处理、适合大数据处理、可构建在廉价机器上等优点,缺点是低延迟数据访问、小文件存取、并发写入、文件随机修改。
Hadoop MapReduce 是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上 TB 级别的海量数据集。这个定义里面有几个关键词:软件框架、并行处理、可靠且容错、大规模集群、海量数据集就是 MapReduce 的特色。

MapReduce 经典代码(wordCount)
上面这段代码就是接收一堆文本数据,统计这些文本数据中每个单词出现的次数。 MapReduce 也是一个计算模型,当数据量很大时,比如 10 个 G ,它可以把这 10G 的数据分成 10 块,分发到 10 个节点去执行,然后再汇总,这就是并行计算,计算速度比你一台机器计算要快的多。
HBase
Hadoop 的主要组件介绍完毕,现在看下 HBase ,它是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用 Hbase 技术可在廉价 PC Server 上搭建大规模结构化存储集群。 HBase 是 Google Bigtable 的开源实现,与 Google Bigtable 利用 GFS 作为其文件存储系统类似, HBase 利用 Hadoop HDFS 作为其文件存储系统; Google 运行 MapReduce 来处理 Bigtable 中的海量数据, HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据; Google Bigtable 利用 Chubby 作为协同服务, HBase 利用 Zookeeper 作为对应。
有人问 HBase 和 HDFS 是啥关系, HBase 是利用 HDFS 的存储的,就像 MySQL 和磁盘, MySQL 是应用,磁盘是具体存储介质。 HDFS 因为自身的特性,不适合随机查找,对更新操作不太友好,比如百度网盘就是拿 HDFS 构建的,它支持上传和删除,但不会让用户直接在网盘上修改某个文件的内容。
HBase 的表有以下特点:
1 ) 大:一个表可以有上亿行,上百万列。
2 ) 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3 ) 稀疏:对于为空( NULL )的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase 提供的访问方式有命令行 shell 方式, java API(最高效和常用的), Thrift Gateway 支持 C++, PHP , Python 等多种语言。
HBase 的使用场景:
需对数据进行随机读操作或者随机写操作;
大数据上高并发操作,比如每秒对 PB 级数据进行上千次操作;
读写访问均是非常简单的操作,比如历史记录,历史订单查询,三大运营商的流量通话清单的查询。

HBase 在淘宝的应用场景
Hive
之前我们说了 MapReduce 计算模型,但是只有懂 Java 的才能撸代码干这个事,不懂 Java 的想用 Hadoop 的计算模型是不是就没法搞了呢?比如 HDFS 里的海量数据,数据分析师想弄点数据出来,咋办?所以就要用到 Hive ,它提供了 SQL 式的访问方式供人使用。
Hive 是由 Facebook 开源, 最初用于解决海量结构化的日志数据统计问题的 ETL(Extraction-Transformation-Loading) 工具, Hive 是构建在 Hadoop 上的数据仓库平台,设计目标是可以用传统 SQL 操作 Hadoop 上的数据,让熟悉 SQL 编程的人员也能拥抱 Hadoop (注意。是数据仓库。不是数据库啊。)
使用 HQL 作为查询接口
使用 HDFS 作为底层存储
使用 MapReduce 作为执行层
所以说 Hive 就是基于 Hadoop 的一个数据仓库工具,是为简化 MapReduce 编程而生的,非常适合数据仓库的统计分析,通过解析 SQL 转化成 MapReduce ,组成一个 DAG(有向无环图)来执行。
Flume
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、 聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时, Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前 Flume 有两个版本 Flume 0.9X 版本的统称 Flume-og , Flume1.X 版本的统称 Flume-ng ,由于 Flume-ng 经过重大重构,与 Flume-og 有很大不同,使用时请注意区分。

Flume 就是一个数据管道,支持很多源(source), sink(目标),和透视宝的 suro 很像,比如拉取 nginx 日志可以拿这个工具简单一配就可用。当然每台 nginx 服务器上都要配置并启动一个 flume.
下面给大家看看配置文件(把 kafka 的数据写入 hdfs 的配置),配置很简单.完全免去了自己写一个 kafka 的 consumer 再调用 hdfs 的 API 写数据的工作量.

YARN
YARN 是 Hadoop 2.0 中的资源管理系统,它的基本设计思想是将 MRv1 中的 JobTracker 拆分成了两个独立的服务:一个全局的资源调度器 ResourceManager 和每个应用程序特有的应用程序管理器 ApplicationMaster ,该调度器是一个 "纯调度器",不再参与任何与具体应用程序逻辑相关的工作,而仅根据各个应用程序的资源需求进行分配,资源分配的单位用一个资源抽象概念 "Container" 来表示, Container 封装了内存和 CPU 。此外,调度器是一个可插拔的组件,用户可根据自己的需求设计新的调度器, YARN 自身提供了 Fair Scheduler 和 Capacity Scheduler 。
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序的提交、与调度器协商资源以启动 ApplicationMaster 、监控 ApplicationMaster 运行状态并在失败时重新启动等。
Ambari
Ambari 是一个集群的安装和管理工具,云智慧之前用的是 Apache 的 Hadoop ,运维同学用源码包安装,一个个配置文件去改,再分发到各个节点,中间哪一步搞错了,整个集群就启动不起来。所以有几个厂商提供 Hadoop 的这种安装和管理平台,主要是 CDH 和 HDP ,国内的很多人都用 CDH 的,它是 Cloudera 公司的,如果用它的管理界面安装,集群节点超过一定数量就要收费了。
Ambari 是 Apache 的顶级开源项目,可以免费使用,现在用的人也很多。 Ambari 使用 Ganglia 收集度量指标,用 Nagios 支持系统报警,当需要引起管理员的关注时(比如,节点停机或磁盘剩余空间不足等问题),系统将向其发送邮件。
ZooKeeper
随着计算节点的增多,集群成员需要彼此同步并了解去哪里访问服务和如何配置, ZooKeeper 正是为此而生的。 ZooKeeper 顾名思义就是动物园管理员,它是用来管大象(Hadoop) 、蜜蜂(Hive) 和 小猪(Pig) 的管理员, Apache Hbase 和 Apache Solr 以及 LinkedIn sensei 等项目中都采用到了 Zookeeper 。 ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,以 Fast Paxos 算法为基础实现同步服务,配置维护和命名服务等分布式应用。
其他组件
以上介绍的都是 Hadoop 用来计算和查询的比较常用和主流的组件,上面那副生态图中的其他几个组件简单了解一下就好:
Pig 是一种编程语言,它简化了 Hadoop 常见的工作任务, Pig 为大型数据集处理提供了更高层次的抽象,与 MapReduce 相比, Pig 提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。
Mahout 是 Hadoop 提供做机器学习用的,支持的算法也比较少,但是一些常用的 k-means 聚类、分类还是有的,他是用 MapReduce 做的,但是 MapReduce 不太擅长这个东西,所以 Mahout 的作者也转投 spark ML 阵营了。
Sqoop 是数据库 ETL 工具,用于将关系型数据库的数据导入到 Hadoop 及其相关的系统中,如 Hive 和 HBase 。 Sqoop 的核心设计思想是利用 MapReduce 加快数据传输速度,也就是说 Sqoop 的导入和导出功能是通过 MapReduce 作业实现的,所以它是一种批处理方式进行数据传输,难以实现实时数据的导入和导出。比如云智慧监控宝以前的业务数据都存在 MySQL ,随着数据量越来越大,要把数据导到 Hbase ,就可以拿 Sqoop 直接操作。
本文所介绍的东西都是用于离线计算的,而之前发布的《面临大数据挑战 透视宝如何使用 Druid 实现数据聚合》则是关于实时计算的框架 Druid 的。大数据常用的流计算框架主要有 Storm , Spark Streaming , Flink , Flink 虽然是 2014 年加入 Hadoop 的,但至今在生产环境上用的人还不多,似乎大家都持观望态度。
说一下流计算(Druid , Spark Streaming)和批处理(MapReduce , Hive)有啥区别,比如电商网站的个性化广告投放,当我们访问了亚马逊搜索笔记本电脑之后,他就会给你推荐很多笔记本电脑链接,你的请求和兴趣爱好被亚马逊服务器实时接收,流计算分析之后当时就会推荐给你可能会购买的东西。如果这个东西拿批处理去做,服务端收集完了,过半个小时才算出你可能要买电脑,这时候再给你推荐电脑明显就不合适了,因为这时候你可能在搜索电炒锅……

最后再说一下大数据的工作流,比如有两个 MapReduce 的任务是有依赖的,必须第一个完成了才能执行第二个,这就需要一个调度工具来调度。 MapReduce 也提供调度的 API ,但是代码要写很多,上面的代码截图只是一部分,这个依赖我写了大概 150 行。所以这时候出现了工作流,用工作流来管理我们的各个 job ,我目前知道的有 oozie 和 azkaban , oozie 的配置比较灵活,推荐大家使用。

 |
1
wander2008 2016-07-28 23:10:11 +08:00 via iPhone
总结还好
|
 |
2
ooonme 2016-07-29 09:02:56 +08:00 via iPhone
竟然没有 spark …
|