
这是一个创建于 3162 天前的主题,其中的信息可能已经有所发展或是发生改变。
大家做故障排查的时候有什么通用的思路和方法吗?能帮助我缩短故障排查时间,尽快解决问题。最好能举例说明下。
 |
1
scys 2016-06-24 12:08:14 +08:00 看日志
|
 |
2
luojiyin87 2016-06-24 15:09:48 +08:00 先 dmesg 看系统的日志.有无系统级别的报错, 在看问题软件的日志. top/htop 查看 进程状态是否有异常.
|
 |
3
cloudwise 2016-06-24 16:26:49 +08:00
前端时间,我们有个客户分享了他的真实经历,我觉得其中有个例子跟主题蛮接近,贴出来看下。
关于移动用户无法访问网站 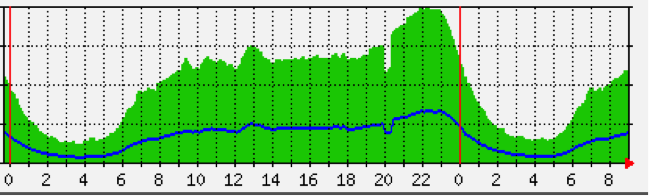 上面是 4 月 21 日交换机的入口出口图,在 20 点整的时候出现一个流量的掉坑,根据这张图可以很明显的看到流量在进来的时候就已经减少了,这个时候系统内部却没发现有其他异常,下面在看下 nginx 的入口出口图 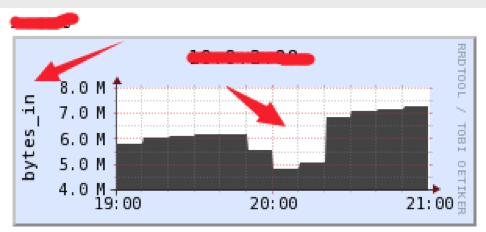 可以很明显的看到也是流量进来就减少了,造成出去的流量减少,那么问题肯定出在外部。 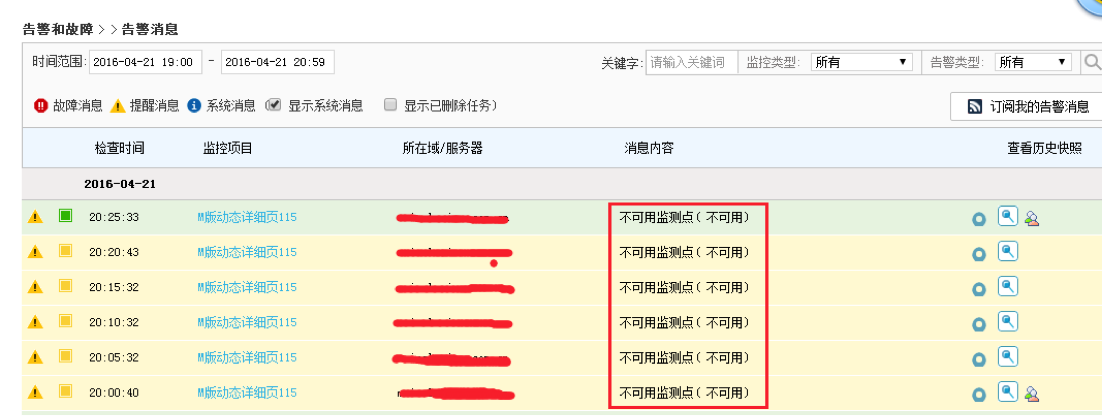 可以很明显的看到 4 月 21 日 20 点持续 25 分钟的移动用户节点无法访问,  这时候就不是我们的事了,而是机房的事,于是马上打电话给机房反馈情况,机房帮我们做了路由优化才解决这过程持续了将近 20 分钟。 |
|
4
cloudwise 2016-06-24 16:29:17 +08:00
图片重新发下:
    |