
这是一个创建于 1984 天前的主题,其中的信息可能已经有所发展或是发生改变。
在上一篇文章中介绍了下载器中间件的一些简单应用,现在再来通过案例说说如何使用下载器中间件集成 Selenium、重试和处理请求异常。
在中间件中集成 Selenium
对于一些很麻烦的异步加载页面,手动寻找它的后台 API 代价可能太大。这种情况下可以使用 Selenium 和 ChromeDriver 或者 Selenium 和 PhantomJS 来实现渲染网页。
这是前面的章节已经讲到的内容。那么,如何把 Scrapy 与 Selenium 结合起来呢?这个时候又要用到中间件了。
创建一个 SeleniumMiddleware,其代码如下:
from scrapy.http import HtmlResponse
class SeleniumMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome('./chromedriver')
def process_request(self, request, spider):
if spider.name == 'seleniumSpider':
self.driver.get(request.url)
time.sleep(2)
body = self.driver.page_source
return HtmlResponse(self.driver.current_url,
body=body,
encoding='utf-8',
request=request)
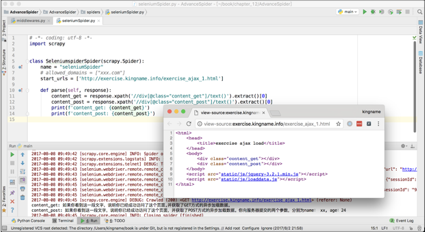
这个中间件的作用,就是对名为“ seleniumSpider ”的爬虫请求的网址,使用 ChromeDriver 先进行渲染,然后用返回的渲染后的 HTML 代码构造一个 Response 对象。如果是其他的爬虫,就什么都不做。在上面的代码中,等待页面渲染完成是通过 time.sleep(2)来实现的,当然读者也可以使用前面章节讲到的等待某个元素出现的方法来实现。
有了这个中间件以后,就可以像访问普通网页那样直接处理需要异步加载的页面,如下图所示。
在中间件里重试
在爬虫的运行过程中,可能会因为网络问题或者是网站反爬虫机制生效等原因,导致一些请求失败。在某些情况下,少量的数据丢失是无关紧要的,例如在几亿次请求里面失败了十几次,损失微乎其微,没有必要重试。但还有一些情况,每一条请求都至关重要,容不得有一次失败。此时就需要使用中间件来进行重试。
有的网站的反爬虫机制被触发了,它会自动将请求重定向到一个xxx/404.html页面。那么如果发现了这种自动的重定向,就没有必要让这一次的请求返回的内容进入数据提取的逻辑,而应该直接丢掉或者重试。
还有一种情况,某网站的请求参数里面有一项,Key 为 date,Value 为发起请求的这一天的日期或者发起请求的这一天的前一天的日期。例如今天是“ 2017-08-10 ”,但是这个参数的值是今天早上 10 点之前,都必须使用“ 2017-08-09 ”,在 10 点之后才能使用“ 2017-08-10 ”,否则,网站就不会返回正确的结果,而是返回“参数错误”这 4 个字。然而,这个日期切换的时间点受到其他参数的影响,有可能第 1 个请求使用“ 2017-08-10 ”可以成功访问,而第 2 个请求却只有使用“ 2017-08-09 ”才能访问。遇到这种情况,与其花费大量的时间和精力去追踪时间切换点的变化规律,不如简单粗暴,直接先用今天去试,再用昨天的日期去试,反正最多两次,总有一个是正确的。
以上的两种场景,使用重试中间件都能轻松搞定。
打开练习页面
http://exercise.kingname.info/exercise_middleware_retry.html。
这个页面实现了翻页逻辑,可以上一页、下一页地翻页,也可以直接跳到任意页数,如下图所示。
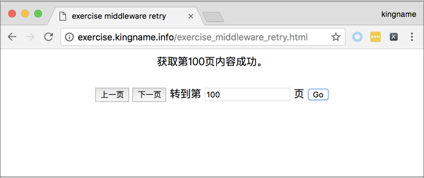
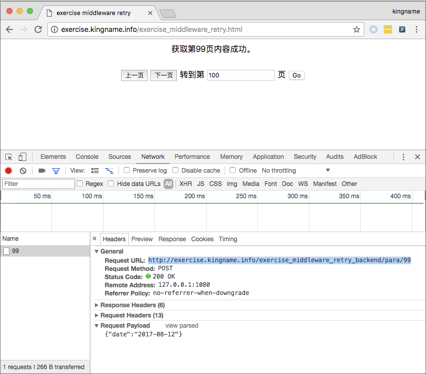
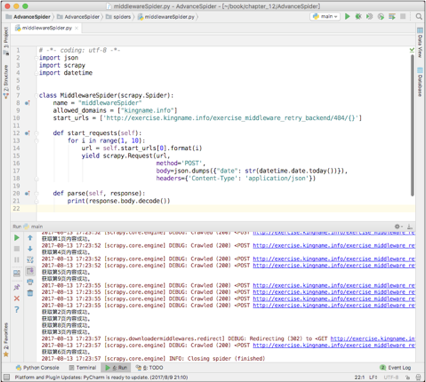
现在需要获取 1 ~ 9 页的内容,那么使用前面章节学到的内容,通过 Chrome 浏览器的开发者工具很容易就能发现翻页实际上是一个 POST 请求,提交的参数为“ date ”,它的值是日期“ 2017-08-12 ”,如下图所示。
使用 Scrapy 写一个爬虫来获取 1 ~ 9 页的内容,运行结果如下图所示。
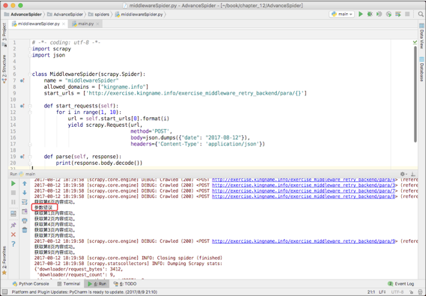
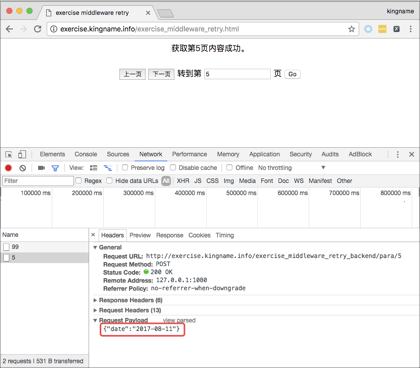
从上图可以看到,第 5 页没有正常获取到,返回的结果是参数错误。于是在网页上看一下,发现第 5 页的请求中 body 里面的 date 对应的日期是“ 2017-08-11 ”,如下图所示。
如果测试的次数足够多,时间足够长,就会发现以下内容。
- 同一个时间点,不同页数提交的参数中,date 对应的日期可能是今天的也可能是昨天的。
- 同一个页数,不同时间提交的参数中,date 对应的日期可能是今天的也可能是昨天的。
由于日期不是今天,就是昨天,所以针对这种情况,写一个重试中间件是最简单粗暴且有效的解决办法。中间件的代码如下图所示。
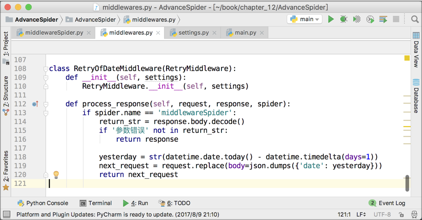
这个中间件只对名为“ middlewareSpider ”的爬虫有用。由于 middlewareSpider 爬虫默认使用的是“今天”的日期,所以如果被网站返回了“参数错误”,那么正确的日期就必然是昨天的了。所以在这个中间件里面,第 119 行,直接把原来请求的 body 换成了昨天的日期,这个请求的其他参数不变。让这个中间件生效以后,爬虫就能成功爬取第 5 页了,如下图所示。
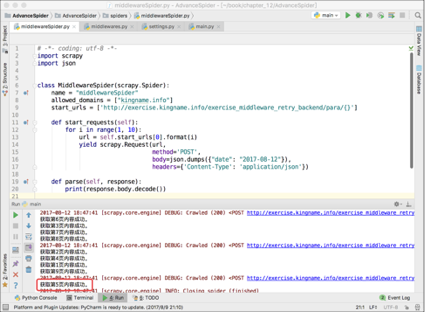
爬虫本身的代码,数据提取部分完全没有做任何修改,如果不看中间件代码,完全感觉不出爬虫在第 5 页重试过。
除了检查网站返回的内容外,还可以检查返回内容对应的网址。将上面练习页后台网址的第 1 个参数“ para ”改为 404,暂时禁用重试中间件,再跑一次爬虫。其运行结果如下图所示。
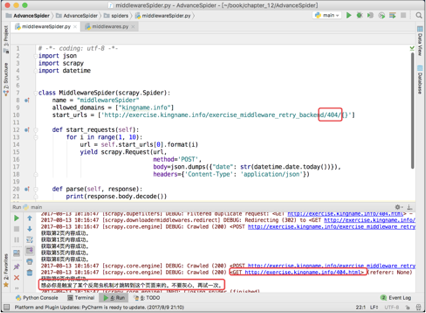
此时,对于参数不正确的请求,网站会自动重定向到以下网址对应的页面:
http://exercise.kingname.info/404.html
由于 Scrapy 自带网址自动去重机制,因此虽然第 3 页、第 6 页和第 7 页都被自动转到了 404 页面,但是爬虫只会爬一次 404 页面,剩下两个 404 页面会被自动过滤。
对于这种情况,在重试中间件里面判断返回的网址即可解决,如下图 12-21 所示。
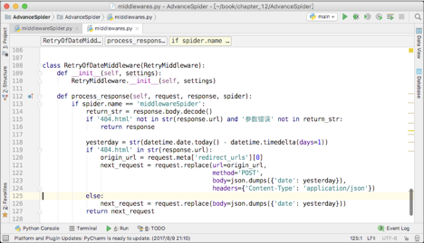
在代码的第 115 行,判断是否被自动跳转到了 404 页面,或者是否被返回了“参数错误”。如果都不是,说明这一次请求目前看起来正常,直接把 response 返回,交给后面的中间件来处理。如果被重定向到了 404 页面,或者被返回“参数错误”,那么进入重试的逻辑。如果返回了“参数错误”,那么进入第 126 行,直接替换原来请求的 body 即可重新发起请求。
如果自动跳转到了 404 页面,那么这里有一点需要特别注意:此时的请求,request 这个对象对应的是向 404 页面发起的 GET 请求,而不是原来的向练习页后台发起的请求。所以,重新构造新的请求时必须把 URL、body、请求方式、Headers 全部都换一遍才可以。
由于 request 对应的是向 404 页面发起的请求,所以 resquest.url 对应的网址是 404 页面的网址。因此,如果想知道调整之前的 URL,可以使用如下的代码:
request.meta['redirect_urls']
这个值对应的是一个列表。请求自动跳转了几次,这个列表里面就有几个 URL。这些 URL 是按照跳转的先后次序依次 append 进列表的。由于本例中只跳转了一次,所以直接读取下标为 0 的元素即可,也就是原始网址。
重新激活这个重试中间件,不改变爬虫数据抓取部分的代码,直接运行以后可以正确得到 1 ~ 9 页的全部内容,如下图所示。
在中间件里处理异常
在默认情况下,一次请求失败了,Scrapy 会立刻原地重试,再失败再重试,如此 3 次。如果 3 次都失败了,就放弃这个请求。这种重试逻辑存在一些缺陷。以代理 IP 为例,代理存在不稳定性,特别是免费的代理,差不多 10 个里面只有 3 个能用。而现在市面上有一些收费代理 IP 提供商,购买他们的服务以后,会直接提供一个固定的网址。把这个网址设为 Scrapy 的代理,就能实现每分钟自动以不同的 IP 访问网站。如果其中一个 IP 出现了故障,那么需要等一分钟以后才会更换新的 IP。在这种场景下,Scrapy 自带的重试逻辑就会导致 3 次重试都失败。
这种场景下,如果能立刻更换代理就立刻更换;如果不能立刻更换代理,比较好的处理方法是延迟重试。而使用 Scrapy_redis 就能实现这一点。爬虫的请求来自于 Redis,请求失败以后的 URL 又放回 Redis 的末尾。一旦一个请求原地重试 3 次还是失败,那么就把它放到 Redis 的末尾,这样 Scrapy 需要把 Redis 列表前面的请求都消费以后才会重试之前的失败请求。这就为更换 IP 带来了足够的时间。
重新打开代理中间件,这一次故意设置一个有问题的代理,于是可以看到 Scrapy 控制台打印出了报错信息,如下图所示。
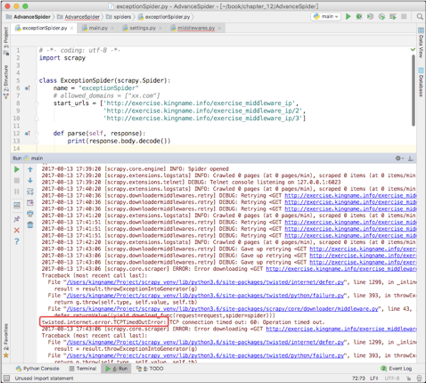
从上图可以看到 Scrapy 自动重试的过程。由于代理有问题,最后会抛出方框框住的异常,表示 TCP 超时。在中间件里面如果捕获到了这个异常,就可以提前更换代理,或者进行重试。这里以更换代理为例。首先根据上图中方框框住的内容导入 TCPTimeOutError 这个异常:
from twisted.internet.error import TCPTimedOutError
修改前面开发的重试中间件,添加一个 process_exception()方法。这个方法接收 3 个参数,分别为 request、exception 和 spider,如下图所示。
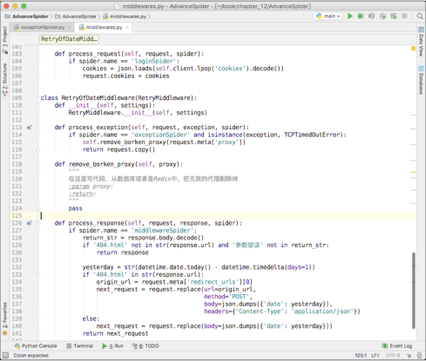
process_exception()方法只对名为“ exceptionSpider ”的爬虫生效,如果请求遇到了 TCPTimeOutError,那么就首先调用 remove_broken_proxy()方法把失效的这个代理 IP 移除,然后返回这个请求对象 request。返回以后,Scrapy 会重新调度这个请求,就像它第一次调度一样。由于原来的 ProxyMiddleware 依然在工作,于是它就会再一次给这个请求更换代理 IP。又由于刚才已经移除了失效的代理 IP,所以 ProxyMiddleware 会从剩下的代理 IP 里面随机找一个来给这个请求换上。
特别提醒:图片中的 remove_broken_proxy()函数体里面写的是 pass,但是在实际开发过程中,读者可根据实际情况实现这个方法,写出移除失效代理的具体逻辑。
下载器中间件功能总结
能在中间件中实现的功能,都能通过直接把代码写到爬虫中实现。使用中间件的好处在于,它可以把数据爬取和其他操作分开。在爬虫的代码里面专心写数据爬取的代码;在中间件里面专心写突破反爬虫、登录、重试和渲染 AJAX 等操作。
对团队来说,这种写法能实现多人同时开发,提高开发效率;对个人来说,写爬虫的时候不用考虑反爬虫、登录、验证码和异步加载等操作。另外,写中间件的时候不用考虑数据怎样提取。一段时间只做一件事,思路更清晰。
本文节选自我的新书《 Python 爬虫开发 从入门到实战》完整目录可以在京东查询到 https://item.jd.com/12436581.html
买不买书不重要,重要的是请关注我的公众号:未闻 Code
公众号已经连续日更三个多月了。在接下来的很长时间里也会连续日更。

目前尚无回复